近期,中国证券业协会对证券行业数字化转型情况进行了调研,并形成《关于推进证券行业数字化转型发展的研究报告》。报告从证券行业数字化转型的必要性角度出发,客观分析了行业数字化转型现状及所面临的挑战,并结合行业调研反馈情况就推进证券行业数字化转型发展提出了相关建议。 《报告》指出,当前我国证券行业信息技术投入依然处于较低水平,证券行业数字化应用水平依然有待提升,证券行业数字化转型人才支撑不足,证券行业数据安全问题亟待解决。 《报告》针对证券行业进行数字化转型给出相关建议: (一)加大引导科技投入,支持行业自主创新 一是优化证券公司分类评价信息技术投入指标。通过进一步明确信息技术投入专项审计要求中的支出类型,合理界定研究开发费用范畴,鼓励证券公司提升自主研发能力, 加大科技人才培养与投入。完善加分标准,提高非运维投入在评价指标中的权重。 二是推广行业数字化转型领域最佳实践。鼓励证券公司在人工智能、区块链、云计算、大数据等领域加大投入,促进信息技术与证券业务深度融合,推动业务及管理模式数字化应用水平提升, 评估数字技术在证券业务领域的应用成果,推广证券行业数字化最佳实践引领行业转型。三是鼓励行业加强信息技术领域的外部合作。支持不同类型的证券公司通过独立研发、合作开发、与第三方科研机构或科技公司协议开发等多种模式,提升行业数字化适应水平和自主可控能力。支持符合条件的证券公司成立或收购 金融科技子公司,并将相关投入纳入信息技术投入指标加分范畴。 (二)增强数字化治理能力,促进业务融合发展 一是加快出台行业标准,促进金融科技应用融合。逐步建立完善人工智能、区块链、云计算、大数据等数字技术在证券行业的应用标准和技术规范,完善人工智能技术在投资顾问业务领域的应用条件及合规要求,引导金融科技在证券领域的稳步探索和有机结合,提升服务实体经济及居民财富管理能力。二是鼓励行业构建数字化战略,深入挖掘发挥数据价值。鼓励证券公司加快数字化运营转型,加强内部数据标准化整合,构建数据中台,实现各业务条线数据标准化采集、集中存储和统一管理,促进行业运用数字技术降本增效。 (三)完善人才发展机制,夯实数字化人才基础 一是明确相关法规要求,畅通数据人才引进。建议根据行业发展需要完善证券公司高管人员任职资格有关规定,适当拓宽相应工作经历及从业年限的认定范畴,将信息技术系统服务机构或其他满足特定条件的科技公司从业经历纳入考虑范围。二是构建长效人才激励机制,激发数据人才活力。建议在评估证券公司实 施股权激励和员工持股计划可行性的基础上出台具体制度规范, 就股权激励或者员工持股计划的有关程序和要求作出明确安排。 允许和鼓励证券公司尤其是金融科技子公司采取更为灵活的激励机制安排。三是健全数据人才培养机制,加强专业人才队伍建设。 建议进一步充实数字化专家库,设计推出精品化、专业化、实践化的数字专业课程,提供更多面向从业人员的专项培训。支持证券公司与高校、科研院所、科技公司联合开展数字人才培养。 (四)强化数据安全保障,坚守防范风险底线 一是加强数据安全技术应用,构建数据安全保障体系。鼓励证券公司与信息技术系统服务机构加强数据加密、数据完整性认证、数据标签、数据脱敏与安全审计等数据安全核心技术的研发和运用。推进建立数据安全标准,并强化在证券行业数字化过程中的推广应用。二是增强数据安全管控,提升业务连续性保障能力。鼓励行业建立数据安全保障动态监测系统,加强行业应对突发事件的处置能力,提升维持业务连续性的保障能力。建立健全行业数据安全通报机制,及时发现、预警、通报、报告重大数据安全事件和漏洞隐患。
8月20日,深交所发布创业板上市委2020年第18次审议会议结果公告,浙江兆龙互连科技股份有限公司(以下简称“兆龙互连”)首发过会。 招股书披露,兆龙互连本次拟发行不超过3062.50万股,占发行后总股本的比例不低于25%。公司拟募集资金4.28亿元,分别用于年产35万公里数据电缆扩产项目、年产330万条数据通信高速互连线缆组件项目、兆龙连接技术研发中心建设项目、补充流动资金。 其中,年产35万公里数据电缆扩产项目拟投入募集资金2.05亿元。兆龙互连表示,数据电缆是公司的主要产品,生产技术成熟,市场认可度较高。随着电子信息产业的发展,市场对于数据电缆的数量与质量都有了更高的需求。公司现有产能已接近饱和,无法满足市场需求。本项目拟于德清县新建数据电缆生产线,将扩大公司生产能力、优化产品结构。 据悉,兆龙互连是专业从事数据电缆、专用电缆和连接产品设计、制造与销售的高新技术企业。自成立以来,发行人凭借自身的技术沉淀、设计能力及品质优势,为境内外客户提供各类产品。公司产品销售覆盖中国、欧洲、北美、中东、东南亚、澳大利亚等多个国家和地区,被广泛应用于网络结构化布线、智能安防、通信设备、数据中心、工业互联网、工业机器视觉、轨交机车和医疗器械等领域。 根据中国机电产品进出口商会统计,2015年至2019年,兆龙互连产品出口额在全国同类产品的出口企业中连续5年排名第1位。 据披露,2017年至2019年,兆龙互连营业收入分别为9.44亿元、11.50亿元、10.97亿元;归属于母公司所有者的净利润分别为3387.82万元、7243.24万元、7526.02万元;扣非净利润分别为4496.05万元、7511.29万元、6611.94万元。 值得一提的是,尽管2020年上半年全球经济受疫情重创,兆龙互连仍然实现营收48783.20万元,较上年同期基本持平;净利润为3066.50万元,同比上升0.93%;扣非净利润达2609.11万元,同比上升9.32%。 兆龙互连表示,公司作为数字通信行业生产企业,下游行业主要为互联网及通信产业,长期来看,随着我国对电子信息、互联网及通信行业规模投资进一步加大,如推进物联网建设进程,促进工业自动化,加快5G建设步伐,布局数据中心等将为数字通信行业带来巨大的市场空间。
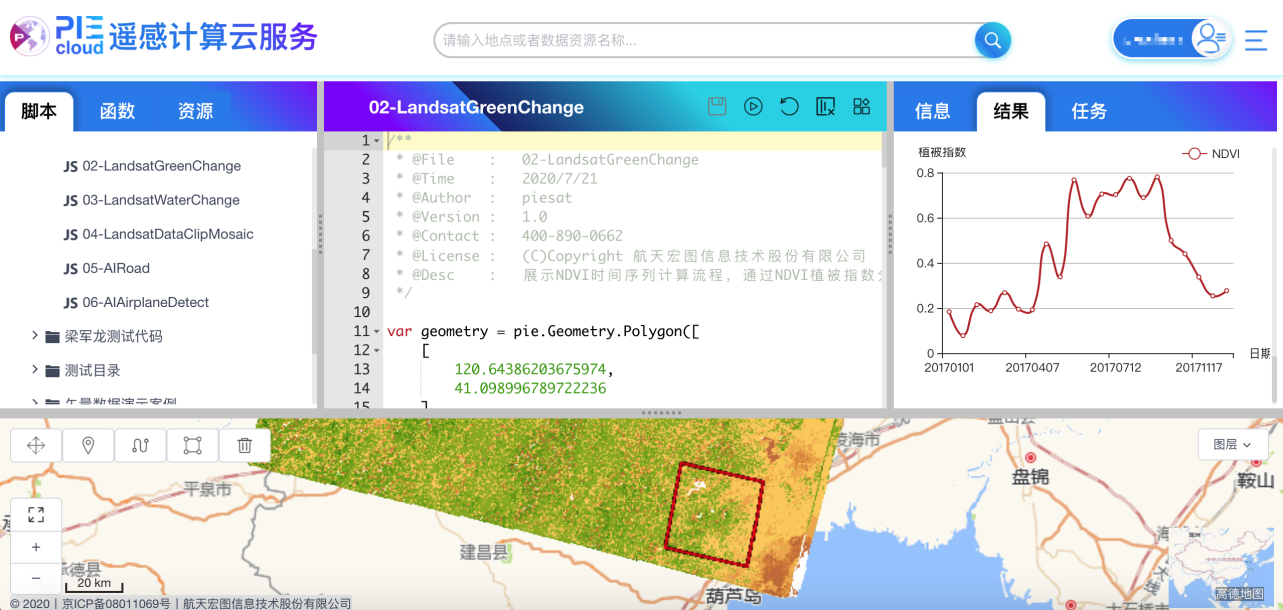
遥感影像大众获取困难、个人电脑算力受限以及遥感处理分析专业性强等因素,制约着遥感大众化的应用和推广。针对以上难题,美国Google公司与卡内基美隆大学和美国地质调查局共同研发并发布了谷歌地球引擎GoogleEarthEngine,实现了全球范围内海量遥感数据的并行处理,为遥感大数据分析提供支撑。该平台的推出极大地提升了国外遥感大众化应用的水平,但是由于特定原因,目前国内科研人员无法直接使用GoogleEarthEngine来做科学研究,同时该国外系统中也没有接入国内的主要卫星遥感数据。为了进一步推动国内遥感技术发展并提升遥感大众化应用水平,研发同类国产软件系统产品是大势所趋。航天宏图依靠多年在遥感行业的技术积累,原生创造了遥感计算云服务平台PIE-Engine。 PIE-Engine作为PIECloud产品家族的重要组成部分,是一个集实时分布式计算、交互式分析和数据可视化为一体的在线遥感云计算开放平台,主要面向遥感科研工作人员、教育工作者、工程技术人员以及相关行业用户。它基于云计算技术,汇集遥感数据资源和大规模算力资源,通过在线的按需实时计算方式,大幅降低遥感科研人员和遥感工程人员的时间成本和资源成本。用户仅需要通过基础的编程就能完成从遥感数据准备到分布式计算的全过程,这使广大遥感技术人员更加专注于遥感理论模型和应用方法的研究,在更短的时间产生更大的科研价值和工程价值。 PIE-Engine是面向所有遥感用户的公众服务平台,不但提供国外的Landsat系列、Sentinel系列卫星遥感数据和国内的高分系列、环境系列、资源系列等卫星遥感数据的访问接口,还包含了大量的遥感通用算法和专题算法。如基于多时相的Landsat和Sentinel数据,可以实时进行作物长势监测、地区旱情分析、水体变化分析、城镇变化监测等分析处理。 PIE-Engine以在线编程为主要使用模式,提供了完善的在线开发环境,包括资源搜索模块、代码存储模块、代码编辑模块、运行交互模块、地图展示模块等。 下面以北京地区植被覆盖情况和东北某地作物长势状况分析来展示一下PIE-Engine的计算能力。 实例一:北京地区植被覆盖情况 北京地区植被覆盖情况分析主要是利用多张影像融合计算NDVI植被指数,分析植被覆盖度情况。在这个例子中首先使用时间和区域条件过滤得到多时态的40多景Landsat8影像,同时基于云量波段实现去云融合,然后针对结果影像计算NDVI指数,最后以北京行政区划矢量裁剪得到最终结果。上述过程全部在云端采用分布式实时计算,PIE-Engine总计算时间小于10秒。用户如果对于某个特定位置的指数值感兴趣,只需用鼠标点击该位置,PIE-Engine将会按需实时计算该位置的NDVI值,并在信息窗口中输出结果。 实例二:植被长势监测 在这个实例中,PIE-Engine利用了指定区域2017年的所有影像(总共30多景),经过实时的去云融合、植被指数计算和区域聚合统计得到了指定范围内的植被指数列表,最终绘制出了该区域的植被长势状况变化图,系统运行时间不到20秒。通过分析结果,可以看到PIE-Engine除了在后台提供实时分布式计算能力外,同样提供了较为丰富的前端开发和可视化能力。 上述范例只是应用PIE-Engine进行遥感专题计算的基础范例,更多的应用需要用户自己在平台上探索和挖掘。PIE-Engine改变了传统遥感影像分析应用的开发形式,降低了技术门槛,用户不用过多关心数据来源、数据存储、资源算力等基础因素,可以更加专注于遥感模型开发、遥感教学实践和行业应用研究,真正实现了“科技改变世界·遥感走进生活”。 作为一款刚刚诞生的全新产品,航天宏图欢迎不同行业、不同背景、不同使用习惯的你们成为第一批用户!目前,PIE-Engine正式迎来了公测,面向公众开放测试使用!公测注册地址:http://engine.piesat.cn。 航天宏图信息技术股份有限公司 地址:北京海淀区益园文化产业基地A区1楼五层 【PIE-EngineQQ交流群】604179645 【联系电话】400-890-0662 【联系邮箱】piecloud_support@piesat.cn (CIS)
8月20日,港股主要指数大幅收跌,恒指一度大跌超2%,尾盘略有回升。截至收盘,恒指跌1.54%,报24791.39点,国指跌1.53%,报10155.81点。今日南下资金净流入17.3亿港元,大市成交额为1181亿港元。 数据来源:Wind 从盘面上看,半导体股和航空股逆势领涨,美兰空港大涨超8%,中芯国际涨3.26%;苹果概念股小幅上涨,瑞声、丘太科技均涨超1.3%;汽车股全线下挫,长城汽车大跌5.6%;乳制品、黄金及贵金属、家电股、电池股、军工股跌幅明显;小米涨2%,美团点评尾盘拉升,收涨1.56%。 数据来源:Wind 数据来源:Wind 汽车股明显下跌,长城汽车大跌超5%领跌,华晨中国、北京汽车、吉利汽车、比亚迪股份等均跟跌。 中汽协根据行业内11家重点企业上报的数据显示,2020年8月上旬,11家重点企业汽车产销分别完成47.3万辆和38.4万辆,与7月上旬相比分别下降24%和15.2%,产量按年增长11.2%,销量按年下降17.9%。其中,乘用车产销分别完成41.5万辆和35.7万辆,与7月上旬相比分别下降19.6%和11.1%。此外,吉利汽车上半年业绩下滑43%,下调全年销售目标6%至132万辆。 数据来源:Wind 黄金股集体走弱,龙资源领跌,中富资源、恒兴黄金、潼关黄金、山东黄金等跟跌。消息面上,受美元反弹拖累,隔夜现货金价受挫。 数据来源:Wind 医疗保健设备股跌幅靠前,中国卫生集团领跌,康德莱医械、微创医疗、威高股份等跟跌。 数据来源:Wind 啤酒股有所下跌,百威亚太跌近4%,华润啤酒跌超3%,青岛啤酒股份跌1.68%。 消息面上,8月20日早间,百威亚太发布2020年中报,2020年上半年,百威亚太收入25.75亿美元,较上年同期下滑26.89%,同期百威亚太股权持有人应占溢利为1.85亿美元。百威亚太总销量于2020年上半年按年减少22.2%,于2020年第二季则按年减少6.1%。 数据来源:Wind 半导体有所走强,节能元件涨25%领涨,上海复旦、中芯国际、康特隆等跟涨。 数据来源:Wind 航空股涨势靠前,美兰空港涨超8%领涨,中国国航、中国东方航空股份、中国南方航空股份等有所拉升。 数据来源:Wind 个股方面,恒指成分股表现分化,其中,中国联通涨2.99%领涨成分股,瑞声科技、创科实业涨幅靠前,蒙牛乳业、友邦保险、九龙仓置业等表现较弱。 数据来源:Wind 数据来源:Wind 与此同时,国指成份股普跌,其中,中国联通、舜宇光学科技、腾讯控股走强国指,蒙牛乳业、中信股份、建设银行等表现较弱。 数据来源:Wind 数据来源:Wind 港股通方面,截至收市,南向合计净流入17.30亿元,其中港股通(沪)净流入6.49亿元,港股通(深)净流入10.81亿元。 数据来源:东方财富 耀才证券表示,港股近日因外围局势影响而未有足够上升动力,旧经济股回吐亦对大市造成压力。从技术上看,只要恒指于短期后市继续站稳25000点关口之上,短线目标该可上移至250天线25800点水平。 艾德证券表示,从技术形态看,短期均线开始上穿长期均线,这是多头的信号。此外,与全球其它市场相比,港股市场明显处于估值低洼区,随着成分股的调整,未来的估值有一定的上升空间。
8月20日,凌志软件发布了2020年半年度报告,上半年营收为2.80亿元,同比减少1.51%;归属于公司股东净利润为7142万元,较去年同期下降11.42%。 尽管在疫情笼罩下,凌志软件营收与去年同期相比基本持平,净利润有所下降,但报告期内研发投入逆势增加:2020年上半年,凌志软件投入研发2651万元,同比增长15.79%。 作为一家中国金融软件外包公司,凌志软件已经为日本主要金融机构服务超过十五年。随着云计算、大数据、人工智能等新一代信息技术融入金融行业,一方面,日本金融机构IT投资持续加大;另一方面,国内金融系统效率优化也迫在眉睫。 凌志软件加大研发投入,企图以先进的技术水平,抓住中、日两方业务增长机遇。那么,其目前取得成效如何?未来又有何布局? 无惧疫情,发现新商机 2016-2019年,凌志软件对日外包业务在整体营收中占比超过了80%,是其主要营收来源。但不同于低附加值的人力外包服务,凌志软件具备核心技术能力,能够提供从咨询设计到系统设计的全过程软件开发。 大数据、云计算、物联网等前沿技术,进一步重塑了软件的技术架构和开发模式,加速了软件与各行业的融合应用。凌志软件为了吸纳新技术,加大了研发投入,2020年上半年研发同比增长15.79%。 尽管全球商业活动受疫情影响较大,但凭借不断提升的技术水平,以及丰富的实践经验,凌志软件不仅对日软件业务稳定,还在疫情中发现了新商机。 在对日软件开发业务方面,以“日本住宅融资机构核心管理平台”项目为例,该项目需要利用微服务框架重构系统,对设计及技术能力要求较高。凌志软件积极组织设计开发工作,确保了项目顺利实施,目前该平台部分功能已交付客户使用。 此外,为应对疫情,凌志软件开发了“快递公司智能化配送管理平台”,利用IOT技术,通过非接触方式读取会员信息、收取快递,同时还允许收货人指定收货地点。此外,该平台还应用了AI技术,基于历史数据计算最佳配送路线,节省了配送成本。 深度服务中国券商 凌志软件虽然主要业务集中日本,但并未放弃中国金融市场:2010年开拓国内业务,现已取得一定影响力,服务了超过60家券商,其中不乏有国泰君安、中信建投等头部客户。 自2004年开始承接日本顶级证券公司的千万级账户管理系统以来,凌志软件将数据处理技术作为主要研发方向之一。 近年来,通过不断加大研发,凌志软件掌握了包括数据采集、数据仓库、数据标签、数据计算、数据洞察等方面的先进技术,支持实时、海量数据的高速处理。并且,为了形成大数据相关的创新解决方案,凌志软件成立了大数据子公司,投资相关领域的企业。 目前,凌志软件的大数据相关解决方案和产品已在国内金融市场落地,其为华泰证券打造的数字化营销平台,能够支撑累计下载装机量超过4500万、月活跃度超过700万的APP;并且,其构建的“千人千面”数字化营销体系,目前在券商行业应用领域排名前列。 此外,中信建投证券“致胜平台”项目,采用了凌志微服务平台(LDSF)作为技术底座,该平台能够帮助前台应用更快速响应业务变化,为后台系统屏蔽技术细节、统一和简化交互模式。截至报告期末,经过多期建设,已经完成中台的整体规划功能。 在全球金融科技浪潮下,日本金融业IT投入稳定增长,国内券商等金融机构迎来业务模式变革。凌志软件加大研发投入,吸纳新技术,在日本业务稳健增长的基础上,收割国内新兴头部券商的增长红利,有望实现业绩新突破。
2020年是不寻常的一年,全球的健康、贸易、经济、文化、政治和科技领域,无不发生着深刻的变化。笔者所在的科技领域,也恰逢现代人工智能(简称AI)发展10周年。前10年,人工智能技术得到了长足的发展,但也留下许多问题有待解决。那么,未来AI技术将会如何发展呢?本文将结合学术界、工业界的研究成果,以及笔者个人研究见解,从算力、数据、算法、工程化4个维度,与读者一起探索和展望AI发展的未来。 一 数据 我们首先分析数据的发展趋势。数据对人工智能,犹如食材对美味菜肴,过去10年,数据的获取无论是数量,还是质量,又或者是数据的种类,均增长显著,支撑着AI技术的发展。未来,数据层面的发展会有哪些趋势呢,我们来看一组分析数据。 首先,世界互联网用户的基数已达到十亿量级,随着物联网、5G技术的进一步发展,会带来更多数据源和传输层面的能力提升,因此可以预见的是,数据的总量将继续快速发展,且增速加快。参考IDC的数据报告(图1),数据总量预计将从2018年的33ZB(1ZB=106GB),增长到2025年的175ZB。 其次,数据的存储位置,业界预测仍将以集中存储为主,且数据利用公有云存储的比例将逐年提高,如图2、图3所示。 以上对于未来数据的趋势,可以总结为:数量持续增长;云端集中存储为主;公有云渗透率持续增长。站在AI技术的角度,可以预期数据量的持续供给是有保证的。 另一个方面,AI技术需要的不仅仅是原始数据,很多还需要标注数据。标注数据可分为自动标注、半自动标注、人工标注3个类别。 那么,标注数据未来的趋势会是怎样的? 我们可从标注数据工具市场的趋势窥探一二,如图4所示。可以看到,人工标注数据在未来的5-10年内,大概率依然是标注数据的主要来源,占比超过75%。 通过以上数据维度的分析与预测,我们可以得到的判断是,数据量本身不会限制AI技术,但是人工标注的成本与规模很可能成为限制AI技术发展的因素,这将倒逼AI技术从算法和技术本身有所突破,有效解决对数据特别是人工标注数据的依赖。 二 算力 我们再来看看算力。算力对于AI技术,如同厨房灶台对于美味佳肴一样,本质是一种基础设施的支撑。 算力指的是实现AI系统所需要的硬件计算能力。半导体计算类芯片的发展是AI算力的根本源动力,好消息是,虽然半导体行业发展有起有落,并一直伴随着是否可持续性的怀疑,但是半导体行业著名的“摩尔定律”已经经受住了120年考验(图5),相信未来5-10年依然能够平稳发展。 不过,值得注意的是,摩尔定律在计算芯片领域依然维持,很大原因是因为图形处理器(GPU)的迅速发展,弥补了通用处理器(CPU)发展的趋缓,如图6所示,从图中可以看出GPU的晶体管数量增长已超过CPU,CPU晶体管开始落后于摩尔定律。 当然,半导体晶体管数量反映整体趋势可以,但还不够准确地反映算力发展情况。对于AI系统来说,浮点运算和内存是更直接的算力指标,下面具体对比一下GPU和CPU这2方面的性能,如图7所示。可以看出,GPU无论是在计算能力还是在内存访问速度上,近10年发展远超CPU,很好的填补了CPU的性能发展瓶颈问题。 另一方面,依照前瞻产业研究院梳理的数据,就2019年的AI芯片收入规模来看,GPU芯片拥有27%左右的份额,CPU芯片仅占17%的份额。可以看到,GPU已成为由深度学习技术为代表的人工智能领域的硬件计算标准配置,形成的原因也十分简单,现有的AI算法,尤其在模型训练阶段,对算力的需求持续增加,而GPU算力恰好比CPU要强很多,同时是一种与AI算法模型本身耦合度很低的一种通用计算设备。 除了GPU与CPU,其他计算设备如ASIC、FGPA等新兴AI芯片也在发展,值得行业关注。鉴于未来数据大概率仍在云端存储的情况下,这些芯片能否在提高性能效率的同时,保证通用性,且可以被云厂商规模性部署,获得软件生态的支持,有待进一步观察。 三 算法 现在我们来分析算法。AI算法对于人工智能,就是厨师与美味佳肴的关系。过去10年AI的发展,数据和算力都起到了很好的辅助作用,但是不可否认的是,基于深度学习的算法结合其应用取得的性能突破,是AI技术在2020年取得里程碑式发展阶段的重要原因。 那么,AI算法在未来的发展趋势是什么呢?这个问题是学术界、工业界集中讨论的核心问题之一,一个普遍的共识是,延续过去10年AI技术的发展,得益于深度学习,但是此路径发展带来的算力问题,较难持续。下面我们看一张图,以及一组数据: 1. 根据OpenAI最新的测算,训练一个大型AI模型的算力,从2012年开始计算已经翻了30万倍,即年平均增长11.5倍,而算力的硬件增长速率,即摩尔定律,只达到年平均增速1.4倍;另一方面,算法效率的进步,年平均节省约1.7倍的算力。这意味着,随着我们继续追求算法性能的不断提升,每年平均有约8.5倍的算力赤字,令人担忧。一个实际的例子为今年最新发布的自然语义预训练模型GPT-3,仅训练成本已达到约1300万美元,这种方式是否可持续,值得我们思考。 2. MIT最新研究表明,对于一个过参数化(即参数数量比训练数据样本多)的AI模型,满足一个理论上限公式: 上述公式表明,其算力需求在理想情况下,大于等于性能需求的4次方,从2012年至今的模型表现在ImageNet数据集上分析,现实情况是在9次方的水平上下浮动,意味着现有的算法研究和实现方法,在效率上有很大的优化空间。 3. 按以上数据测算,人工智能算法在图像分类任务(ImageNet)达到1%的错误率预计要花费1亿万亿(10的20次方)美元,成本不可承受。 结合前文所述的数据和算力2个维度的分析,相信读者可以发现,未来标注数据成本、算力成本的代价之高,意味着数据红利与算力红利正在逐渐消退,人工智能技术发展的核心驱动力未来将主要依靠算法层面的突破与创新。就目前最新的学术与工业界研究成果来看,笔者认为AI算法在未来的发展,可能具有以下特点: ?? (1)先验知识表示与深度学习的结合 纵观70多年的人工智能发展史,符号主义、连接主义、行为主义是人工智能发展初期形成的3个学术流派。如今,以深度学习为典型代表的连接主义事实成为过去10年的发展主流,行为主义则在强化学习领域获得重大突破,围棋大脑AlphaGo的成就已家喻户晓。 值得注意的是,原本独立发展的3个学派,正在开始以深度学习为主线的技术融合,比如在2013年,强化学习领域发明了DQN网络,其中采用了神经网络,开启了一个新的研究领域称作深度强化学习(Deep Reinforcement Learning)。 那么,符号主义类算法是否也会和深度学习进行融合呢?一个热门候选是图网络(Graph Network)技术,这项技术正在与深度学习技术相融合,形成深度图网络研究领域。图网络的数据结构易于表达人类的先验知识,且是一种更加通用、推理能力更强(又称归纳偏置)的信息表达方法,这或许是可同时解决深度学习模型数据饥渴、推理能力不足以及输出结果可解释性不足的一把钥匙。 (2)模型结构借鉴生物科学 深度学习模型的模型结构由前反馈和反向传播构成,与生物神经网络相比,模型的结构过于简单。深度学习模型结构是否可以从生物科学、生物神经科学的进步和发现中吸取灵感,从而发现更加优秀的模型是一个值得关注的领域。另一个方面,如何给深度学习模型加入不确定性的参数建模,使其更好的处理随机不确定性,也是一个可能产生突破的领域。 (3)数据生成 AI模型训练依赖数据,这一点目前来看不是问题,但是AI模型训练依赖人工标注数据,是一个头痛的问题。利用算法有效解决或者大幅降低模型训练对于人工标注数据的依赖,是一个热点研究领域。实际上,在人工智能技术发展过程中一直若隐若现的美国国防部高级研究计划局(DARPA),已经将此领域定为其AI3.0发展计划目标之一,可见其重要程度。 (4)模型自评估 现有的AI算法,无论是机器学习算法,还是深度学习算法,其研发模式本质上是通过训练闭环(closed loop)、推理开环(open loop)的方式进行的。是否可以通过设计模型自评估,在推理环节将开环系统进化成闭环系统也是一个值得研究的领域。在通信领域,控制领域等其他行业领域的大量算法实践表明,采用闭环算法的系统在性能和输出可预测性上,通常均比开环系统优秀,且闭环系统可大幅降低性能断崖式衰减的可能性。闭环系统的这些特性,提供了对AI系统提高鲁棒性和可对抗性的一种思路和方法。 四 工程化 上文已经对人工智能数据、算力、算法层面进行了梳理和分析,最后我们看看工程化。工程化对于人工智能,如同厨具对于美味佳肴一样,是将数据、算力、算法结合到一起的媒介。 工程化的本质作用是提升效率,即最大化利用资源,最小化减少信息之间的转换损失。打一个简单的比喻,要做出美味佳肴,食材、厨房灶台、厨师都有,但是唯独没有合适的厨具,那么厨师既无法发挥厨艺(算法),又无法处理食材(数据),也无法使用厨房灶台的水电气(算力)。因此,可以预见,工程化未来的发展,是将上文提到的算力与算法性能关系,从现在的9次方,逼近到理论上限4次方的重要手段之一。 过去10年,AI工程化发展,已形成一个明晰的工具链体系,近期也伴随着一些值得关注的变化,笔者将一些较为明显的趋势,汇总如下: 总结来说,AI工程化正在形成从用户端到云端的,以Python为编程语言的一整套工具链,其3个重要的特点为:远程编程与调试,深度学习与机器学习的GPU加速支持,以及模型训练与推理工具链的解耦。与此同时,产业链上游厂商对开源社区的大量投入,将为中下游企业和个人带来工具链的技术红利,降低其研发门槛和成本,笔者认为微软、脸书、英伟达3家上游厂商主推的开源工具链尤其值得关注。 五 结语 对于人工智能技术过去10年发展取得的成就,有人归因于数据,也有人归因于算力。未来人工智能技术发展,笔者大胆预测,算法将是核心驱动力。同时,算法研发的实际效率,除了算法结构本身,还取决于设计者对先进工具链的掌握程度。 未来10年,科技界是否能用更少的数据,更经济的算力,获得真正意义上的通用智能呢?我们拭目以待。
2020年是不寻常的一年,全球的健康、贸易、经济、文化、政治和科技领域,无不发生着深刻的变化。笔者所在的科技领域,也恰逢现代人工智能(简称AI)发展10周年。前10年,人工智能技术得到了长足的发展,但也留下许多问题有待解决。那么,未来AI技术将会如何发展呢?本文将结合学术界、工业界的研究成果,以及笔者个人研究见解,从算力、数据、算法、工程化4个维度,与读者一起探索和展望AI发展的未来。一数据我们首先分析数据的发展趋势。数据对人工智能,犹如食材对美味菜肴,过去10年,数据的获取无论是数量,还是质量,又或者是数据的种类,均增长显著,支撑着AI技术的发展。未来,数据层面的发展会有哪些趋势呢,我们来看一组分析数据。首先,世界互联网用户的基数已达到十亿量级,随着物联网、5G技术的进一步发展,会带来更多数据源和传输层面的能力提升,因此可以预见的是,数据的总量将继续快速发展,且增速加快。参考IDC的数据报告(图1),数据总量预计将从2018年的33ZB(1ZB=106GB),增长到2025年的175ZB。其次,数据的存储位置,业界预测仍将以集中存储为主,且数据利用公有云存储的比例将逐年提高,如图2、图3所示。以上对于未来数据的趋势,可以总结为:数量持续增长;云端集中存储为主;公有云渗透率持续增长。站在AI技术的角度,可以预期数据量的持续供给是有保证的。另一个方面,AI技术需要的不仅仅是原始数据,很多还需要标注数据。标注数据可分为自动标注、半自动标注、人工标注3个类别。那么,标注数据未来的趋势会是怎样的?我们可从标注数据工具市场的趋势窥探一二,如图4所示。可以看到,人工标注数据在未来的5-10年内,大概率依然是标注数据的主要来源,占比超过75%。通过以上数据维度的分析与预测,我们可以得到的判断是,数据量本身不会限制AI技术,但是人工标注的成本与规模很可能成为限制AI技术发展的因素,这将倒逼AI技术从算法和技术本身有所突破,有效解决对数据特别是人工标注数据的依赖。二算力我们再来看看算力。算力对于AI技术,如同厨房灶台对于美味佳肴一样,本质是一种基础设施的支撑。算力指的是实现AI系统所需要的硬件计算能力。半导体计算类芯片的发展是AI算力的根本源动力,好消息是,虽然半导体行业发展有起有落,并一直伴随着是否可持续性的怀疑,但是半导体行业著名的“摩尔定律”已经经受住了120年考验(图5),相信未来5-10年依然能够平稳发展。不过,值得注意的是,摩尔定律在计算芯片领域依然维持,很大原因是因为图形处理器(GPU)的迅速发展,弥补了通用处理器(CPU)发展的趋缓,如图6所示,从图中可以看出GPU的晶体管数量增长已超过CPU,CPU晶体管开始落后于摩尔定律。当然,半导体晶体管数量反映整体趋势可以,但还不够准确地反映算力发展情况。对于AI系统来说,浮点运算和内存是更直接的算力指标,下面具体对比一下GPU和CPU这2方面的性能,如图7所示。可以看出,GPU无论是在计算能力还是在内存访问速度上,近10年发展远超CPU,很好的填补了CPU的性能发展瓶颈问题。另一方面,依照前瞻产业研究院梳理的数据,就2019年的AI芯片收入规模来看,GPU芯片拥有27%左右的份额,CPU芯片仅占17%的份额。可以看到,GPU已成为由深度学习技术为代表的人工智能领域的硬件计算标准配置,形成的原因也十分简单,现有的AI算法,尤其在模型训练阶段,对算力的需求持续增加,而GPU算力恰好比CPU要强很多,同时是一种与AI算法模型本身耦合度很低的一种通用计算设备。除了GPU与CPU,其他计算设备如ASIC、FGPA等新兴AI芯片也在发展,值得行业关注。鉴于未来数据大概率仍在云端存储的情况下,这些芯片能否在提高性能效率的同时,保证通用性,且可以被云厂商规模性部署,获得软件生态的支持,有待进一步观察。三算法现在我们来分析算法。AI算法对于人工智能,就是厨师与美味佳肴的关系。过去10年AI的发展,数据和算力都起到了很好的辅助作用,但是不可否认的是,基于深度学习的算法结合其应用取得的性能突破,是AI技术在2020年取得里程碑式发展阶段的重要原因。那么,AI算法在未来的发展趋势是什么呢?这个问题是学术界、工业界集中讨论的核心问题之一,一个普遍的共识是,延续过去10年AI技术的发展,得益于深度学习,但是此路径发展带来的算力问题,较难持续。下面我们看一张图,以及一组数据:1. 根据OpenAI最新的测算,训练一个大型AI模型的算力,从2012年开始计算已经翻了30万倍,即年平均增长11.5倍,而算力的硬件增长速率,即摩尔定律,只达到年平均增速1.4倍;另一方面,算法效率的进步,年平均节省约1.7倍的算力。这意味着,随着我们继续追求算法性能的不断提升,每年平均有约8.5倍的算力赤字,令人担忧。一个实际的例子为今年最新发布的自然语义预训练模型GPT-3,仅训练成本已达到约1300万美元,这种方式是否可持续,值得我们思考。2. MIT最新研究表明,对于一个过参数化(即参数数量比训练数据样本多)的AI模型,满足一个理论上限公式:上述公式表明,其算力需求在理想情况下,大于等于性能需求的4次方,从2012年至今的模型表现在ImageNet数据集上分析,现实情况是在9次方的水平上下浮动,意味着现有的算法研究和实现方法,在效率上有很大的优化空间。3. 按以上数据测算,人工智能算法在图像分类任务(ImageNet)达到1%的错误率预计要花费1亿万亿(10的20次方)美元,成本不可承受。结合前文所述的数据和算力2个维度的分析,相信读者可以发现,未来标注数据成本、算力成本的代价之高,意味着数据红利与算力红利正在逐渐消退,人工智能技术发展的核心驱动力未来将主要依靠算法层面的突破与创新。就目前最新的学术与工业界研究成果来看,笔者认为AI算法在未来的发展,可能具有以下特点:(1)先验知识表示与深度学习的结合纵观70多年的人工智能发展史,符号主义、连接主义、行为主义是人工智能发展初期形成的3个学术流派。如今,以深度学习为典型代表的连接主义事实成为过去10年的发展主流,行为主义则在强化学习领域获得重大突破,围棋大脑AlphaGo的成就已家喻户晓。值得注意的是,原本独立发展的3个学派,正在开始以深度学习为主线的技术融合,比如在2013年,强化学习领域发明了DQN网络,其中采用了神经网络,开启了一个新的研究领域称作深度强化学习(Deep Reinforcement Learning)。那么,符号主义类算法是否也会和深度学习进行融合呢?一个热门候选是图网络(Graph Network)技术,这项技术正在与深度学习技术相融合,形成深度图网络研究领域。图网络的数据结构易于表达人类的先验知识,且是一种更加通用、推理能力更强(又称归纳偏置)的信息表达方法,这或许是可同时解决深度学习模型数据饥渴、推理能力不足以及输出结果可解释性不足的一把钥匙。(2)模型结构借鉴生物科学深度学习模型的模型结构由前反馈和反向传播构成,与生物神经网络相比,模型的结构过于简单。深度学习模型结构是否可以从生物科学、生物神经科学的进步和发现中吸取灵感,从而发现更加优秀的模型是一个值得关注的领域。另一个方面,如何给深度学习模型加入不确定性的参数建模,使其更好的处理随机不确定性,也是一个可能产生突破的领域。(3)数据生成AI模型训练依赖数据,这一点目前来看不是问题,但是AI模型训练依赖人工标注数据,是一个头痛的问题。利用算法有效解决或者大幅降低模型训练对于人工标注数据的依赖,是一个热点研究领域。实际上,在人工智能技术发展过程中一直若隐若现的美国国防部高级研究计划局(DARPA),已经将此领域定为其AI3.0发展计划目标之一,可见其重要程度。(4)模型自评估现有的AI算法,无论是机器学习算法,还是深度学习算法,其研发模式本质上是通过训练闭环(closed loop)、推理开环(open loop)的方式进行的。是否可以通过设计模型自评估,在推理环节将开环系统进化成闭环系统也是一个值得研究的领域。在通信领域,控制领域等其他行业领域的大量算法实践表明,采用闭环算法的系统在性能和输出可预测性上,通常均比开环系统优秀,且闭环系统可大幅降低性能断崖式衰减的可能性。闭环系统的这些特性,提供了对AI系统提高鲁棒性和可对抗性的一种思路和方法。四工程化上文已经对人工智能数据、算力、算法层面进行了梳理和分析,最后我们看看工程化。工程化对于人工智能,如同厨具对于美味佳肴一样,是将数据、算力、算法结合到一起的媒介。工程化的本质作用是提升效率,即最大化利用资源,最小化减少信息之间的转换损失。打一个简单的比喻,要做出美味佳肴,食材、厨房灶台、厨师都有,但是唯独没有合适的厨具,那么厨师既无法发挥厨艺(算法),又无法处理食材(数据),也无法使用厨房灶台的水电气(算力)。因此,可以预见,工程化未来的发展,是将上文提到的算力与算法性能关系,从现在的9次方,逼近到理论上限4次方的重要手段之一。过去10年,AI工程化发展,已形成一个明晰的工具链体系,近期也伴随着一些值得关注的变化,笔者将一些较为明显的趋势,汇总如下:总结来说,AI工程化正在形成从用户端到云端的,以Python为编程语言的一整套工具链,其3个重要的特点为:远程编程与调试,深度学习与机器学习的GPU加速支持,以及模型训练与推理工具链的解耦。与此同时,产业链上游厂商对开源社区的大量投入,将为中下游企业和个人带来工具链的技术红利,降低其研发门槛和成本,笔者认为微软、脸书、英伟达3家上游厂商主推的开源工具链尤其值得关注。五结语对于人工智能技术过去10年发展取得的成就,有人归因于数据,也有人归因于算力。未来人工智能技术发展,笔者大胆预测,算法将是核心驱动力。同时,算法研发的实际效率,除了算法结构本身,还取决于设计者对先进工具链的掌握程度。未来10年,科技界是否能用更少的数据,更经济的算力,获得真正意义上的通用智能呢?我们拭目以待。





 登录
登录






 工商服务
工商服务 危机公关
危机公关 金融律师
金融律师 app开发
app开发 财税服务
财税服务 金融牌照
金融牌照 网站建设
网站建设 知识产权
知识产权 企业征信
企业征信 审计评估
审计评估