在国际经济环境复杂严峻、国内发展任务艰巨繁重的背景下,我国数字经济依然保持较快增长,各领域数字经济稳步推进,质量效益明显提升。 中国信息通信研究院日前发布的《中国数字经济发展白皮书(2020年)》(以下简称“白皮书”)显示,2019年我国数字经济增加值规模达到35.8万亿元,占GDP比重达到36.2%,其中北京、上海数字经济GDP占比已经超过50%。数字经济规模再创历史新高,数字经济各领域发展亮点频出。 专家指出,数字经济是农业经济、工业经济之后的一种新的经济社会发展形态,能够减少信息流动障碍,加速资源要素跨产业、跨区域合理流动。推动我国经济的数字化和智能化转型,不仅能够创造大量投资机会,有效拓展国内需求,还能推动技术创新和产业变革,形成更多新的增长点和增长期。 各行业数字化转型加快 “2019年我国数字经济增长15.6%,应该还是保持一个快速增长势头,这也反映了中国实体经济各个行业数字化转型正在逐步加快。”中国信通院副院长余晓晖在接受媒体采访时说。 近年来,我国数字经济蓬勃发展,已经成为国民经济中核心增长极之一。白皮书显示,我国数字经济增加值规模由2005年的2.6万亿元扩张到2019年的35.8万亿元,数字经济占GDP比重由2005年的14.2%提升至2019年的36.2%。 数字经济持续高速增长,已成为我国应对经济下行压力的关键抓手。白皮书显示,按照可比口径计算,2019年我国数字经济名义增长15.6%,高出同期GDP名义增速约7.85个百分点,高出同期第一产业名义增速6.8个百分点,高出同期第二产业名义增速9.79个百分点,高出同期第三产业名义增速6.54个百分点。与2005年相比,我国数字经济规模增长12.7倍,年复合增长率高达20.6%;而同期GDP仅增长4.3倍,年复合增长率为12.6%;第一产业、第二产业和第三产业分别增长2.2倍、3.4倍和5.9倍,年复合增长率分别为8.7%、11.1%和14.8%。由此可以看出,数字经济已成为推动经济持续稳定增长的关键动力。 我国数字经济的地位更加突出。白皮书指出,数字经济对GDP增长的贡献率不断提升,从2014年到2019年的6年时间,数字经济对GDP增长的贡献率始终保持在50%以上,2019年数字经济对GDP增长的贡献率为67.7%,成为驱动我国经济增长的核心关键力量。 数字经济各领域亮点频出 据中国信通院相关负责人介绍,此次发布《中国数字经济发展白皮书(2020年)》,是2015年以来连续第六次发布数字经济研究成果。 这位负责人介绍说,白皮书的一大看点是,数字经济框架从“三化”扩展到“四化”。 在延续以往研究的基础上,白皮书将“三化”(数字产业化、产业数字化、数字化治理)扩展为“四化”(数字产业化、产业数字化、数字化治理、数据价值化),增加了对数据价值化、数字经济政策体系的研究梳理。从“四化”各个角度看,我国数字经济各领域发展亮点频出。 其一,数字产业化稳步增长。2019年,数字产业化增加值规模达7.1万亿元,占GDP比重为7.2%,同比增长11.1%。数字产业结构持续优化,软件产业和互联网行业占比分别同比增长2.15个百分点和0.79个百分点,电信业、电子信息制造业占比小幅回落。 其二,产业数字化稳步推进。产业数字化转型由单点应用向连续协同演进,传统产业利用数字技术进行全方位、多角度、全链条的改造提升,数据集成、平台赋能成为推动产业数字化发展的关键。2019年,我国产业数字化增加值规模约为28.8万亿元,占GDP比重为29.0%。产业数字化加速增长,成为国民经济发展的重要支撑力量。 其三,数字化治理稳步提升。基于大数据的决策支撑能力、综合治理能力建设成效明显,规范有序、包容审慎、鼓励创新、协同共治的数字经济发展环境加速形成。 其四,数据价值化加速推进。数据生产要素属性的提升,关系着经济增长的长期动力。随着数字化转型加快,数据对提高生产效率的乘数效应凸显,成为最具时代特征的新生产要素。 战略勾画数字经济发展蓝图 我国发展数字经济对于经济长远健康发展具有重要意义。 国务院发展研究中心原副主任王一鸣指出,基于数字技术的新产业、新业态、新模式是对冲我国经济下行压力的稳定器,数字经济将开启新一轮经济周期,成为后疫情时期经济复苏的引擎。 当前和今后一段时间,是全球数字经济发展的重大战略机遇期。白皮书从五个方面提出数字经济发展建议:一是加速数据要素价值化进程。推进数据采集、标注、存储、传输、管理、应用等全生命周期价值管理,实现传感、控制、管理、运营等多源数据一体化集成。二是推进实体经济数字化转型。加强企业数字化改造,引导实体经济企业加快生产装备的数字化升级。三是着力提升产业基础能力。突破核心关键技术,强化基础研究,提升原始创新能力,占据创新制高点。四是强化数字经济治理能力。建立健全法律法规,完善数据开放共享、数据交易、知识产权保护、隐私保护、安全保障等法律法规。五是深化数字经济开放合作。加强各国数字经济领域政策协调,深度参与全球数字经济创新合作等。 针对我国数字经济发展问题,王一鸣也提出了建议:一是制定数字经济发展战略,围绕新基建关键技术研发、产业数字化转型等进行战略勾画,引导市场主体广泛参与,形成政府与企业合作推动的数字化经济发展合力。二是推进新型基础设施建设,鼓励市场主体继续扮演重要角色,引导市场主体参与新基建,更好地对接市场的终端需求。三是加强关键共性技术的研发和产业化,在人工智能、物联网等前沿领域提前布局。四是加快制造业数字化转型,推进企业数字化改造,发挥龙头企业数字化转型的示范引领作用,带动产业链和中小企业数字化水平的提升。五是进行包容审慎的监管,监管机构不仅要关注数字平台的形成,更需要关注竞争机制是否有效、竞争秩序是否有序以及如何更好地保护消费者权益。六是解决数据产权的界定问题,对个人数据、政务数据以及商业数据进行分类界定和保护,建立安全、自由的数据流通环节,为培育数据市场创造条件。
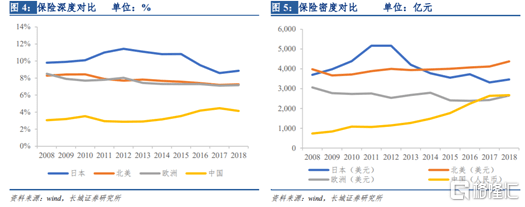
最近,美国互联网保险公司Lemonade(LMND.US)成功登陆纽交所一事,吸引了不少投资者的目光。 挂牌当日,Lemonade股价飙涨近140%,市值突破30亿美元,一跃成为2020年迄今表现最好的IPO。截至发稿,该公司股价上涨至78.79美元,市值已触及43.25亿美元。 从股价及涨幅情况来看,Lemonade的表现优于美股保险板块中不少公司,针对这一“突围”现象,不乏市场热议。笔者认为,除近期美股市场整体环境利好外,其他重要推动因素主要在于:Lemonade是一家以AI技术运营的新型互联网保险公司。 与此同时,同于年内登陆纳斯达克的“保险电商第一股”——慧择(HUIZ.US),近期股价也见大幅拉升之势。该公司目前股价较4月中旬的历史低位水平,最高涨幅已逾60%。 后疫情时代中,互联网保险赛道或迎新的爆发?一起来聊聊这门生意,对标Lemonade,探索下中国本土互联网保险公司慧择的投资价值。 中国保险市场前景向好,互联网细分赛道快速成长 回顾中国保险业体量的增长,可以说是越来越快。总资产方面,自1979年国内保险业复业,保险业总资产达到1万亿,用时25年;达到10万亿,用时10年;突破20万亿,仅用时5年。年度保费方面,自2009年保费收入首次达到万亿后,于2014年突破2万亿,于2019年迈进4万亿大关。 另据瑞士再保险公司2019年发布的第三份sigma报告,到2029年,中国有望占据全球保险市场20%的份额,成为全球最大的保险市场。 但实际上,中国保险业仍属于朝阳产业,从深度和密度水平来看,中国的保险市场仍远远落后于美国与许多发达国家。 2018年,北美、日本和欧洲的保险深度分别为7.26%、8.86%和7.17%,保险密度分别为4377美元、3466美元和2655美元,而同期我国保险深度为4.14%,保险密度为2724元人民币,仅是美国的十分之一、日本的八分之一。伴随中国经济不断发展,居民风险保障意识逐渐增强,保险行业还有巨大的发展空间。 具化到互联网领域而言,传统保险存量市场的切分促使互联网保险行业亦呈高速发展之势。据IBIS World 发布的2020年市场研究报告,从2015年到2020年,在线保险的市场规模的年均增长率约为9.0%。作为在线保险业务的代表,在线保险经纪市场预计在2020年将达到313亿美元。 同时,据《后疫情时期中国保险需求的18大发现》显示,疫情之前,互联网保险的转化率较去年增长约73%,疫情期间,转化率较去年大增至232%。综合叠加疫情催化数字化转型、激发市场需求等因素来看,互联网保险行业具备巨大的市场潜力。 对标 Lemonade,慧择产品结构及盈利能力更胜一筹 谈及Lemonade和慧择,这两家企业的商业逻辑颇有相同之处,但深入探究来看又十分不同。 相似的是,Lemonade和慧择同处互联网保险赛道,瞄准年轻用户,且两者均注重AI布局,具备核心竞争力。 用户圈层而言,两家公司均在互联网主要消费群体——年轻用户中站稳了脚跟。招股书显示,2018年Lemonade约70%的客户年龄在35岁以下,90%的客户表示以前没有买过保险产品,2019年用户数量超过64万名,较2018年翻了一倍多;而根据慧择上市后的首份年报,2019年平台已累计投保用户630万,平均年龄仅32岁,且多为来自一二线城市的新兴中产阶级。 商业模式而言,Lemonade完全基于应用人工智能和大数据分析等技术,其所有服务一律是移动客户端和PC端自动执行,只有当聊天机器人无法处理时才有人工介入。在业务过程中,其通过构建“取证图”,以 AI和行为经济学来检测和阻止欺诈。 慧择的理念是“经营用户”,更看重服务深度和专业度,走的是以技术和数据智能驱动产品销售和客户服务的发展路线。近期,其已正式与西南财经大学大数据研究院展开合作以搭建保险大数据知识图谱。从功能上看,“知识图谱”融合保险产品、疾病数据等多维度信息,便于全面量化分析,助于保险深度关系发现、推理、构筑AI基础,与Lemonade 的“取证图”有异曲同工之处。 实际上,保险业是第一个由数据驱动的产业,构建知识体系对保险服务链条价值具备重大意义。可以说,数据赋能业务、深化数据算法与保险服务场景融合能力,是互联网保险市场中的核心竞争力之一。 不同的是,Lemonade和慧择的产品结构存在本质差别,盈利能力表现不一。 Lemonade没有出售由知名保险公司支持的保单,而是在自己的资产负债表上保留索赔责任。目前,该公司的保险产品种类较为集中,虽然自今年2月其新推出电子产品、家具、服装、宠物等多种保险,并表示今后可能会选择以承销商或代理人的身份进入其他险种市场,但如今来看,其主要险种仍为面向租客和业主的房屋保险。 产品过于单一,自然会在一定程度上限制盈利空间。资料显示,自2015年开展业务以来,Lemonade就一直没有盈利。具体看来,2019年公司净亏损约1.09亿美元,较上年同期扩大105%;2020年Q1,公司净亏损3650万美元,较上年同期扩大69%。 相对之下,慧择的产品结构和盈利能力明显更胜一筹。 慧择选择通过平台承销保险产品,以收取佣金的方式创收,轻资产模式无需承担任何投资和承保风险。其创始团队从2006年就开始探索线上保险,积累多年经验已走出独特的盈利模式,并将销售长期险作为重点战略布局。2019年,慧择已经与国内70家保险公司建立了合作关系,平台提供了约1352款保险产品,涵盖健康险、人寿险、意外险、旅游险、企业险等在内的全险种。不仅如此,凭借平台累积的海量数据优势,慧择更与合作保险公司共同开发具吸引力和竞争力的定制产品。 值得一提的是,慧择自2018年实现扭亏为盈后,已连续八个季度盈利。2019年,慧择平台促成总保费约2.89亿美元,实现营收约1.43亿美元,Non-GAAP净利润约1579万美元。其中,销售长期保险产品的保费于总保费中的占比约为87.4%,由此可见,长期险的高佣金率和续期保费对于增加客户粘性、创造可持续收入的作用尤为明显。 小结 长期来看,保险是一个非常值得期待的行业,这一点国外已经充分验证,中国保险业仍属于朝阳产业,还有很大的发展空间。 就本文提到的“赛道选手”Lemonade和慧择而言,两者都属这个新兴赛道的热门选手,均精准触达互联网消费群体,注重AI布局,彰显出互联网保险的核心能力,具备一定关注价值。 尤其是扎根本地“土壤”的慧择,已用大数据优势证明自己的核心价值和增长引擎动力,且考虑到其主打长期险种,而长期健康险有望在疫情下半场收获正面红利等因素,笔者认为,在互联网保险行业这场盛宴中,慧择有望进一步扩张,打开市场想象空间。 此外,资本市场方面,近日花旗首次覆盖慧择并予以“买入”评级,目标价10.6美元,而慧择当前股价水平较该目标价格,仍有理想上涨空间。
十年前提起金融科技,人们多半在谈金融信息化建设,世界还没有互联网金融和人工智能应用的姓名。如今,我们立在2020这个山头前后张望,会惊觉变革无时无刻不在各个维度发起,林海翻涛,遍地生辉。为技术创新冲在最前线者有之,为规模化应用落地奋斗者亦有之;传统的金融业务场景和流程被拆解成更细的颗粒,逐步数字化、智能化翻新;解决方案的整体化、平台化特性也逐渐彰显。我们试图从这些维度出发,找出金融科技下一个十年的「先锋阵列」。还有人在争辩谁是前浪后浪,而最敏锐的航海者已经分清潮水的方向。互金巨头的科技赋能「脚本」互金企业集体转型升级,改造传统信贷流程,告别粗放式经营,选择强调自己的科技赋能角色,是过去数年里最受关注的金融科技趋势之一。在今年企业们披露的年报数据中我们可以看见,这样的转型之举已经初有成效。首次将科技收入独立出来的360金融,可以说是行业代表之一。在2019年报里,360金融将收入调整为传统收入和科技收入两部分,以反映公司加码科技的战略决心,以及更加全面真实地反映公司科技转型的业务形态。2019年,360金融传统收入为人民币80.13亿元,科技收入则为12.06亿元,增速高达336%,这一数字在2018年为228%。科技服务占比稳步上升,由年初的0.8%跃升到年底的22%。在电话会议上,CEO吴海生宣布,预计到2020年底,在新增业务中,科技驱动业务量占比将提高到30-50%。360金融对科技业务的总结陈词,某种程度上也概括了互金企业们的转型意图:当金融周期真正到来,传统业务将面临利润大幅缩水的风险;相比之下,科技业务赚取的是智能获客、智能风控这样的技术服务费,虽然在短期牺牲了一定的利润,但由于不承担金融风险,业务稳健性将会加强。具体到业务环节,几组数据或许更能说明这家企业的科技投入效果:截至2019年12月31日,360金融累计注册用户1.35亿,较2018年底增长71.3%;授信用户2472万,同比增长97.1%;在360金融的帮助下获得贷款的用户达到1591万,较2018年增长92.1%。摩根士丹利在报告中指出,运营效率应当兼顾借款用户的数量及质量。在2018年2季度至2019年3季度之间,360金融每季获取新客户超过150万人,远高于同业上市公司。中金公司的报告则表示,2019年,360金融拳头产品360借条的月均MAU达1511万人,月均DAU为165万人,两项排名都位列同类公司之首。逾期率方面,截至2019年12月31日,360金融的M3+逾期率为1.5%。从用户增速和质量不难看出,360金融在获客运营方面颇有心得。该公司表示,这得益于贯穿业务全流程的人工智能技术的应用,例如借助全自动化算法智能投放,利用实时数据和用户全生命周期标签实现智能运营。另外,贷后环节中,智能机器人自动完成+AI机器人的大量应用,极大提高了面向海量用户的服务效率和质量,提升了客户黏性。360金融透露称,其78%的催收工作、77%的电话营销工作、91%的客户服务工作都由相应的机器人完成,即便由人工完成的部分也实现了AI质检机器人的100%覆盖检查。运营的多个环节自主研发了近百款机器人,申请了近四百项发明专利。值得一提的是,360金融在2019年12月上线智信引擎业务,通过数据智能技术构筑生态圈。该业务一方面连接优质和分散的互联网流量场景平台,拓展多元流量变现通道。拍拍贷母公司信也科技,同样是值得注意的典型案例。在科技领域更上一层楼的决心,不只体现在名字的更改上。根据最新财报数据,2020年一季度,信也科技的研发费用为8760万元,这一数字在上一季度(2019Q4)为9310万元。截至2020年5月20日,信也科技共登记软件著作权139项,另有已授权及申请中的专利130项。信也科技称,对业务全流程的精细化运营以及技术微创新是后续科技投入的重点。针对日常流量投放存在的数据分离、批量投放困难、无法实时监控和预警等痛点,信也科技也自主研发了章鱼流量管理平台,其能够通过定位实时数据链路、效果评估、决策优化引擎、智能投放平台,实现媒体渠道精准触达目标客户群体,挖掘潜在用户。解决方案的平台化「历练」在金融科技的下一个十年里,可以预见的是,技术服务商们的产品会更注重整体化、平台化,不再是普通的单点输出。生物识别在金融领域的应用进程,就是由点到线及面,如今正在形成覆盖多渠道、多场景、多模态识别融合的平台解决方案。随着金融业务线上化的蓬勃发展,用户授权环节身份确认的方式日益多样化,涉及的业务场景也不仅是开户、支付。每个业务系统“各自为政”建立独立的身份识别方式,不仅会造成资源浪费,也为后期数据管理、同步维护等方面增加了难度。将多种不同生物识别认证方式集成到一个统一平台中,实现系统间数据整合、资源共享,对于认证效率和系统安全性来说至关重要。身份认证作为金融业务的第一道风控关卡,对技术服务商的综合素质要求不亚于「特种兵」:既要有对不同生物特征的优秀识别能力,又要对金融不同场景逻辑和痛点理解透彻,有强大的数据处理分析能力,以及服务本身足够灵活高效。作为最早一批将生物识别技术引入到银行内部强安全认证业务中的企业,眼神科技是业内率先推动多模态融合,并将多模态融合识别做到平台级的排头兵,拿下了金融行业超过80%的客户。眼神科技打造的ABIS多模态生物识别统一平台,建立在其人脸、虹膜、指纹、指静脉及多模态生物识别融合算法基础上,通过轻量化、高效扩展的微服务架构和丰富标准的服务接口,实现一站式的识别认证服务、统一的数据管理服务及智慧化的运维服务,可以做到按需灵活组合、快速扩展。对金融机构而言,KYC不会只是“认识你的客户”这样简单,要将金融服务上升到“懂得你的客户”层面,而金融科技公司正是这关键一跃的「主演」。眼神科技的这一平台也通过与银行大数据平台的融合,高效、稳定地为客户提供数据分析与识别能力,帮助各大银行为客户提供智能化、个性化的服务体验,增强海量客户数据的风险防控能力,助力银行步入生物识别大数据客户营销时代。目前,眼神科技的ABIS多模态生物识别统一平台在金融行业多场景中已得到广泛应用,包含互联网渠道、柜面业务、自助银行、智慧网点等,在确保客户信息和账户安全的同时,打造优越的客户体验。交通银行、邮储银行、民生银行、华夏银行、渤海银行和数家省级农信社等众多金融机构均已引入。此外,眼神科技也将多模态生物识别融合技术赋能金融以外的更多场景,如学校、社区、政府、公安等,实现了行业合作的深度融合。谁能率先实现数据安全和隐私保护的最高目标?去年下半年的大数据行业震荡,和本月《数据安全法》的正式出台,无一不指向同一个技术趋势:实现数据可用不可见,保证数据安全和隐私保护。在监管更严格、业务更敏感的金融行业,数据的安全有序使用自然被调到了更高的优先级。能够在这一方面上率先获得实质性进展的金融科技企业,自然也有望引领行业趋势。重新审视数据的获取、共享,到使用和加工,链条的每一环都有不小的漏洞,学术界相继出现了安全多方计算、可信执行环境、隐私计算、联邦学习、共享智能等解决路线,在数据控制、处理或实现方式上各有不同。联邦学习这一研究分支,正是在微众银行首席人工智能官杨强教授团队和其领导的IEEE联邦学习标准制定委员会的推动下,成为当今全球人工智能产学两界最受关注的领域之一。从简单定义来讲,联邦学习是在本地,把本地数据建模,模型的关键参数加密,数据加密传到云端也无法解密。云端用算法将数据包们加以聚合,来更新现有模型,模型更新后下传。重要的是,整个过程中,云端服务器不知道每个数据包里的内容。这种多个参与方(如移动设备或整个组织)协作式地训练模型的机器学习方法,将不再需要将分散的训练数据搜集到一起,数据不出本地的特性让数据使用全过程都变得更为安全可靠。在杨强教授带领下开展联邦学习研究的微众银行,内部已投入百余人,打造了一个覆盖技术上下游的联邦学习团队,包含研究、学术、研发、商业、行业应用等多个细分队伍。他们已申请100+项相关专利,牵头推进IEEE联邦学习国际标准与联邦学习国家标准制定。2019年2月,微众银行开源了联邦学习框架FATE,这也是全球首个工业级联邦学习开源框架,能够解决包括计算架构可并行、信息交互可审计、接口清晰可扩展在内的三个工业应用常见问题。它给开发者提供了实现联邦学习算法和系统的范本,大部分传统算法都可以经过一定改造适配到联邦学习框架中来,用户体验上和传统建模差异较小。微众AI团队也发起了「联邦学习生态」(FedAI Ecosystem),在确保数据安全及用户隐私的前提下,建立基于联邦学习的 AI 技术生态,使得各行业更充分发挥数据价值,推动垂直领域案例落地。目前微众已将联邦学习用于金融领域,通过合法合规的多维度联邦数据建模,小微企业风控模型效果约可提升12%,相关企业机构有效节约了信贷审核成本,整体成本预计下降5%-10%,并因数据样本量的提升和丰富,风控能力进一步增强。在微众看来,联邦学习不仅具有加速AI创新发展、保障隐私信息和数据安全的公共价值;从商业层面上看,联邦系统更是一个“共同富裕”的策略,能带动跨领域的企业级数据合作,催生基于联合建模的新业态和模式。
线上开会、远程诊疗、直播带货、无人配送……新冠肺炎疫情的出现,深刻影响着人们参与经济社会活动的方式,也给各类企业带来了全新的考验。如何利用数字化技术,实现“隔而不离、生意照做”,成为摆在中国企业乃至整个中国经济面前的必答题。 日前,国家信息中心信息化和产业发展部与京东数字科技研究院联合发布《携手跨越 重塑增长——中国产业数字化报告2020》(以下简称《报告》),通过对大量产业数字化转型案例的研究,描绘出当前中国产业数字化的现状、特征与内涵。《报告》认为,面对疫情考验,不少中国企业积极推进数字化升级,提升管理效能、降低运营成本,产业数字化正在为经济增长注入“数字动力”。 数字化改变产业形态 风味鱼皮饺、锅上叉烧、顺德鱼面、鸡汤炒菜心……初到广东,吃上一顿地道的粤菜料理,是不少消费者心仪的选项。粤菜之所以名扬四海,离不开粤菜大厨的精心烹饪。不过,6月22日,碧桂园旗下千玺餐饮机器人集团打造的FOODOM天降美食王国机器人餐厅综合厅在广东顺德正式开业,同样吸引了不少“吃货”们的注意。 在约2000平方米的餐厅内,20余种核心技术自主研发的“机器人大厨”同时上岗。从中餐区门口进入,迎面是硕大的落地玻璃幕墙,墙内18口炒锅机器人整齐列阵。客人扫码点单后,机器人机械臂迅速启动,按照既定程序开始炒菜。食客们不仅可以亲眼看到机器人炒菜的每一个“动作”,而且还能享受自动上菜服务。 “机器人大厨”怎么会做地道粤菜呢?据千玺机器人餐饮集团总经理邱咪介绍,“机器人大厨”的每一个动作,都是工程师们基于10位知名粤菜大厨的烹饪动作数据得出的标准化操作流程。与传统菜品相比,自动化、标准化的机器人烹饪制作过程,排除人为干扰因素,不仅保障菜品品质稳定,也大大提高了生产效率。 这只是数字化改变产业形态的一个缩影。 “当前,信息化、网络化、数字化、智能化交织演进,网联、物联、数联、智联迭代发展,我们正在迈入一个以数字化生产力为主要特征的新阶段。”国家信息中心信息化和产业发展部主任单志广对本报记者说。 据单志广介绍,产业数字化是在新一代数字科技支撑和引领下,对产业链上下游的全要素数字化升级、转型和再造的过程。其具有“以数字科技变革生产工具”“以数据资源为关键生产要素”“以数字内容重构产品结构”“以信息网络为市场配置纽带”“以服务平台为产业生态载体”等特征。 产业数字化,正帮助中国企业降本增效。《报告》显示,通过建设数字化车间或智能工厂,企业生产效率平均提升37.6%、能源利用率平均提升16.1%、运营成本平均降低21.2%、产品研制周期平均缩短30.8%、产品不良率平均降低25.6%。国家信息中心最新测算显示,2019年中国共享经济市场交易额为32828亿元,比上年增长11.6%,未来3年,仍将保持年均10%以上的增速。 企业借“智”力实现转型 实践中,数字化正在帮助越来越多的中国企业“育新机”“开新局”。 ——农业养殖更精准。在京东数科在与首农畜牧的合作中,数字化让养牛成为“美差”:饲养员不用频繁去看是否要给奶牛加料,实时监测网能够实时监测到食槽内剩料量;技术人员不用按传统的触摸法对奶牛综合体况进行评估,摄像头结合AI算法可无接触式自动化对牛每天进行体况评分…… 其中,智能喷淋系统可通过AI技术识别牛只的精准定位,结合AI算法以及对温湿度指数、风速等多个维度,来为奶牛进行精准喷淋,能帮助产奶量提高30%,节水效率提高60%。 ——装备制造更高效。在湖南长沙,中联重科望城工业园内的高空作业机械智能制造工厂是新一代信息技术与制造装备深度融合与创新的典范。在明亮洁净的智能化生产车间里,每条生产线上的设备与人互联互通,实现各道工序无缝对接。智能灵活的机器人手臂顺畅实现原材料激光切割、工件焊接和部件喷涂,AGV智能输送车替代传统人工完成上下物料移动和运送,自动安全的RGV有轨制导车和EMS空中输送线轻松实现精准配送。 “通过制造执行系统(MES)平台,我们的生产计划根据车间情况,将每道工序分解下达到不同设备和时间段进行精细执行;车间内部,计划排产、作业执行、数据采集、在制品管理、库存管理、质量管理等形成全闭环管理,让海量信息智能互联,环环紧扣,获得有效管理和共享。”中联重科高空作业机械公司总经理助理王建介绍。 ——医疗服务更安全。海尔集团数据平台总经理熊媛媛介绍,通过运用物联网科技,海尔打造的“血液网”让每袋血有了身份证,让分布在血站、医院的每个冷柜组成了一张虚拟大网,确保血液保存、使用的全过程100%安全可控。 熊媛媛对本报记者表示,数据是企业核心的资产,海尔一直很重视数据,内部开会一切以数据说话。同时,海尔也在积极探索数据在用户体验、智能决策、资产赋能等方面的应用和创新。“未来产品会被场景替代,行业会被生态覆盖,企业像热带雨林一样才能生生不息,这是我们数字化重生的目标和方向。” 让企业“敢转”“会转” 京东数字科技集团首席经济学家、京东数科研究院院长沈建光接受记者采访时表示:“面对疫情影响,主导人工智能、大数据、5G、物联网等领域的科技企业将不断向经济社会各个领域渗透。科技企业,不光是对老百姓提供直接的服务,而且向各种各样的工厂和商家提供升级换代的数字化改造,从而成为产业数字化的重要支撑点。”沈建光介绍,很多数据都存在于传统行业,进行数字化改造可以更好地挖掘潜力。在这个过程中,创造共同利益、实现融合共赢,才能把产业数字化更快地向前推进。 企业借助数字化实现转型升级面临哪些挑战?据单志广介绍,国内企业数字化转型比例约25%,远低于欧洲的46%和美国的54%。同时,有超过55%的国内企业尚未完成基础的设备数字化改造。 “疫情期间,不少企业转战互联网探索数字化转型,智能机器人、远程办公、直播电商、无接触贷款、在线销售、在线培训、在线服务等成为更多企业的新选择,但由于数字化转型技术挑战强、业务再造难、转换成本高、短期收益低、试错风险大,企业普遍存在‘不想转、不敢转、不会转’的问题。”单志广说。 对于这些问题,政策层面频繁发力。 3月,工业和信息化部印发《中小企业数字化赋能专项行动方案》,明确13项重点任务和4项推进措施,提出着力运用信息技术加强疫情防控,加快发展在线办公、在线教育等新模式,培育壮大共享制造、个性化定制等服务型制造新业态。 5月,国家发改委牵头制定发布《数字化转型伙伴行动倡议》,提出以搭建“中央部委—地方政府—平台企业—行业龙头企业—行业协会—服务机构—中小微企业”联合推进机制为核心,创新性地构建起政府和社会各界联手开展数字化转型精准帮扶的生态体系。 单志广表示,京东、腾讯等大企业可以发挥更大作用。一方面,针对中小微企业数字化转型所需的资源,共建数字化技术及解决方案社区,利用共享经济、平台经济等开放模式,对中小微企业开展低成本、低门槛、快部署服务;另一方面,可以结合自身优势,协同推进供应链要素数据化和数据要素供应链化,支持打造“研发+生产+供应链”的数字化产业链,推动平台间数据和服务的互联互通,最终加速形成“各得其所、互利共赢”的产业数字化生态。
支付宝7日提供的最新数据显示,自搜索板块新增数十万金融类关键词以来,搜索人次增长近50%,搜索次数也增长两倍。 搜索框是用户获取支付宝服务核心入口之一。今年6月17日,支付宝搜索板块升级,新增数十万金融类搜索关键词,以简化用户获取金融服务的流程。目前通过搜索框获取服务的用户中,50%都在搜索金融类服务。 支付宝数据还显示,近期“抗疫国债发行”成为最热关键词。支付宝理财平台相关负责人介绍,长期价值型产品逐渐受到青睐,三年期产品关注度与销量直线上升。医药类基金则因其股票市场的出色表现,包揽三大基金门类业绩第一。
对百度来说,联邦学习+金融会产生怎样的火花?此次课程,他将分享基于联邦学习技术的百度金融安全计算平台(度信)建设与实际应用,讲述如何借力安全技术架构、脱敏方法和合规制度设计,在“用户充分授权、数据来源合法合规”前提下,打破数据孤岛,实现多方数据加密融合建模,助力金融企业业务的开展。以下为谢国斌演讲全文内容,AI金融评论做了不改变原意的编辑:百度智能云的数据孤岛破解之道我们在跟很多的金融客户进行沟通的时候,他们普遍面临的痛点,就是数据孤岛和隐私保护的问题。目前的现状是,一方面要保护客户的隐私,另外一方面,数据孤岛在不同的程度上存在着,去年央行发布的金融科技三年发展规划里,也强调了要“消除信息的壁垒;数据融合。”今年4月,国务院也在《关于构建更加完善的要素市场化配置体制机制的意见》里,强调了数据的共享、数据资源的整合和安全保护。所以,“数据孤岛”和“隐私保护”两者的困境,在业内一直是个难题。行业里做这块技术的公司,一般有如下路径在积极探索:其中一种就是联邦学习;还有与之接近的,就是在做参数交换、梯度交换的时候,会用到的多方安全计算。另一种以硬件加密为主,可信计算(TEE),在内存里做安全加密。以及基于云安全,做安全隔离域的方法。基于刚才说到的痛点,百度推出了度信金融安全计算平台,做数据融合,前提是强调用户要充分授权,数据来源要合法、合规。也提出了联合建模产品,拒绝数据孤岛的存在,产品对上面几种路径都是支持的。今天的要点,主要是分享在联邦学习和多方安全计算技术路径上,我们所做的尝试和产品的研发。我们的金融安全计算平台有以下特点:平台主要服务于金融行业to B客户,会考虑行业里特别关注的一些场景,比如营销、风控、投研、反欺诈。我们基于金融的建模,有一些专用的功能点增强。从安全特性上,无论硬件软件,有多种的方式进行技术加固。金融云专区上,我们通过了国家的四级等级保护;数据流通方面,我们今年通过了信通院的相关技术测评。从计算建模层面看,我们是自主操作,甲方乙方各自操作,全程免编码,流程很简单,性能比同类的算法也要快。私有云、公有云和私有化方面,我们有多种方式部署,产品目前也能提供工业级的使用体验,包括严格的工程封装、项目的验证实测,还有百度沉淀的金融行业案例、提供金融行业的场景的解决方案。度信金融安全计算平台的技术方案我们这个平台建设,刚才提到用三大类技术方案,统一前端入口和统一后台架构。后台的架构,从下往上看,分为执行层、应用层、操作层、场景层。从执行层看,中间是基于多方计算的联邦学习引擎,引擎最下面是基于加密的密码学算法和一些常用的不经意传输、同态加密、密钥分享等。往上是基于密码学算法的多方安全计算,双方或多方的加密数据的协调和交换,隐私的PSI对齐、ID化、联邦分析和联邦学习。再往上是应用层一些基于模型的算法的应用,这个是标准的机器学习建模流程。操作层有可视化的操作平台和4A安全赋能金融行业,打造营销风控端对端的场景化建模功能。我们的平台架构,需要满足三个不同的客户需求:定制化方案要满足客户不同的安全等级要求;有客户对建模要求较高,那对算子、算法、模型多样性、交互和应用性方面要求就高一些,我们也会提供类似的解决方案。还有对不同的资源配置,构建私有云、公有云和专有云支撑,支持不同的部署方案。这个平台的操作很简单,就是三个步骤。先是合作的AB双方,完成本地数据的上传。原则上都是上传到自己的IDC机房里,数据不出域。第二步细分为几个小步骤:1.数据的融合,会通过隐私保护的求交技术PSI,达到双方的数据的可用不可见。强调一下,融合不会泄露双方的数据隐私,比如说甲方有一亿的客户,B方有5000万的客户,双方去求交集,求出来只有500万客户,那么我们只知道这500万的交集,剩下的客户群双方都是不知道的。即使求交了这500万的客户,我们也只有某一个主要的使用方,比如甲方银行在使用的时候,才知道这500万相互求交的客户号码是什么。2.求交的这批客户,我们会进行简单的特征工程,一些算法模型训练,包括像机器学习的逻辑回归、GBDT等,也按照这个数据拆分,做完模型训练、输出模型报告以后,进行模式部署、模型推理和预测发布。第一步上传样本比较简单,把数据上传以后,摁一个按键,就会看到这一横行里数据的上传成功,然后AB双方在这个地方点鼠标发布,数据才传到本地的服务器上面。第二步模型训练,会自动包含刚才说的样本对齐,包括可选的特征工程,还有算法参数、算法选择等。在模型训练过程中,等它出来一个结果,就会有一些像我这里截屏的模型,配置基本信息,比如双方对齐了多少样本,有哪一些特征?这里只能看到特征名称。我们算法所涉及的每一个主要参数是什么样的。这里以逻辑式回归为例,生成模型评估报告,像ROC、KS值等等,就完成整个模型训练。第三步就是模型预测,需要在页面新建预测任务名称,包括描述,还有我们选择哪个预测的模型。生成的模型在这里做选择,再选择要预测的数据集,点蓝色按钮完成整个模型预测过程。一定时间后,就会看到右下角预测成功的显示,整个模型的离线预测就完成了,也可以用新建预测服务以API的方式供外调用。我们平台的设计理念,是全程免编码,通过鼠标的拖拽来完成的。度信平台在银行业、保险业的应用银行信贷产品的互联网营销这家银行开展信贷业务时,需要通过互联网去线上获客,但它并没有这种线上资源或流量去投放,也没有相关风险管理经验,于是它就跟某家互联网公司进行渠道上的联合建模,实现精准获客和控制风险。首先是银行把他的数据和互联网合作方,把数据在自己的机房里边准备好,然后各自联邦学习时,上传梯度参数。在互联网渠道这一端,主要是上传数据,建模发生在银行这端自行操作,就完成了整个建模过程,达到了数据模型建设,完成后确定合适人群。第三步,精准广告投放,包括精准获客,这部分我们项目的客户日均调用量是50万笔。整体贷后表现非常好,降低了风险,也节约了这家银行的成本。线上风控+联邦学习因为银行没有过往的一些互联网行为信息,也需要为此通过互联网渠道来合作、来进行联合建模。联邦学习最后的效果就是,让申请率提升了,通过率又稳定在一定的范围内,不良率低于银行业同业平均水平。这个案例,我们推送的贷款客户金额是超过千万;通过率控制在稳定范围;该案例的不良贷款率是0.38 ,比去年银行业1.81的不良率低了不少。不同险种交叉营销这个案例是一家车险公司的业务,在客户里筛选健康险的意向用户,进行精准点对点促销。建模流程与上个案例类似,由保险公司提供的高响应人群样本和互联网公司的数据进行融合训练,最后结果运用于全量的车险客户群。效果上,这个模型的AUC值达到了0.76,减少了对客户的打扰,也降低了营销的成本。联邦学习落地金融的关键技术点联邦学习本质上是软件加密技术,数据不出域、不出本企业,主要是通过梯度参数出域。从本质上来说是去中心化的方案。横向联邦由谷歌在2016年的时候研发出来,即数据的水平切分,主要用于金融同业间的数据融合。横向联邦学习的计算步骤主要有四:双方发送加密的梯度,安全的聚合,发送聚合的加密梯度参数,再解密梯度更新模型。纵向联邦学习基于数据的垂直细分,主要用于金融业和非金融行业,特别是像一家银行和一家互联网公司的数据融合。两家公司的客户群很多时候是重叠的,特征互补。首先有分发公钥,加密交换中间的结果,再进行加密梯度和损失的计算,然后更新模型。在和金融企业沟通的时候,我们发现他们关注的点有这些:整个联邦学习里,金融企业运用最多的是纵向联邦学习,金融机构更想看到的是和他非同业之间的数据融合。银行在和第三方机构合作时,非常强调这些数据进来以后,对指标的一些增量贡献,在意的是在现有基础上的提升。如果在现有基础上,引入的数据源没有很大幅度的提升、效果不明显,对金融机构的吸引力就会降低。同时金融机构也强调数据源的差异化,如果数据来源都很类似,那对指标的贡献、对模型效果,提升度不是很大。联邦学习是整个框架里的主要技术。另外,多方安全计算所涉及的加密技术,其主要原理如图左所示,四个参与方在针对任何一方都没有可信的情况下,安全地进行多方协同计算。在一个分布式的网络中,多个的参与实体各自持有秘密的输入,完成对某函数的计算;但是要求每一个参与实体,除了计算的最终结果以外,其他的中间过程,包括自己其他客户的原始数据,任何的输入数据都是不可以看到、都是不可以获得的,这保证了参与各方的数据的安全性。在安全计算过程中,所用到的一些密码学或加密技术,概括起来有这么七种。混淆电路,来自于物理学电路原理:一堆人各自拥有隐私数据,想把数据合起来进行计算,但又不想把数据交换给别人,典型的案例就是百万富翁问题。不经意传输,服务的某一个接收方,以不经意的方式得到服务的发送方输入的一些信息、信号,这样就可以保护接受者的隐私不被发送者所知道。秘密的比较协议,计算的双方各输入一个数值,但是他们又希望在不向对方泄露自己的数据的前提下,比较出这两个数的大小。同态加密,用这种方法先计算,后解密,也等价于先解密后计算。同态加密里也有加法同态、乘法同态,包括全同态、偏同态、半同态等,它在联邦学习中应用也较多。秘密分享,将秘密分割存储,多个参与者要相互协作才能恢复秘密的消息,如果有一方没有参与,是没有办法把这个秘密完全恢复出来的。零知识证明,证明者能够在不向验证者提供任何有用的信息情况下,使验证者相信某个论断是正确的。差分隐私,这在业界应用也比较多。百度在多方安全计算方面,有自己的MPC平台架构。我们的平台架构分为这么六层,从基础到应用,有运行环境基于DOCKER的,还有基于云和SERVER的。在基础的运行环境往上,有刚才说到的六七种加密算法。再往上是整个系统包括TLS、4A这一块的安全。再往上是系统平台层,有用户角色管理,包括数据和分布式调度、监控等。再往上看是数据的接入,再到数据的应用。下面我会重点介绍三类算法,都是百度自研的。第一种是逻辑回归,逻辑回归是常用的二分类的分类器,在这种分类器上面我们加了一个基于PrivC的加密算法的逻辑回归,这种算法是基于MPC的安全学习。我们在19年的安全顶会上面发表了关于这个算法的文章,特点是训练速度和在公开的服务器上的明文相比,速度大概会是在明文算法的40倍以内,也就是明文算法假如要用时1分钟,那么我们要用时40分钟。这里有一个案例,就是我们基于深度MNIST公开数据集,6万行784位的运算,我们用时25秒,时间还是比较快的。在下面的截图,我们看到一些Table2,在一些加减还有一些常规的比较上面,基于我们自研的PrivC的算法和公开的其他的一些加密算法,像ABY、EMP、SPDZ等等,我们的运算速度都比他们快,标出的黑色数值是越小越好。我们的准确率和明文算法比,会达到99%左右,比明文算法低一点点,一般的梯度,有时候建模如果控制得不太好,都会有一些模型的损耗,而我们的损耗是比较少的。第二种算法,就是基于梯度提升的算法,有GBDT、XGBoost,再快一点的有LightGBM,我们这种算法叫SecureGBM,它是在LightGBM级别的基础上改造而成的。基于 LightGBM基础上改造而成的这种算法,我们也是发表在19年的IEEE国际大数据会议上,大家看到左下角有一个截图,红色的框是百度自研的叫SecureGBM,蓝色的框,LightGBM-(A,B)就是明文算法,我们算法最后的结果和同类的最好的明文算法去比,在没有用任何加密的和普通的建模相同的条件下,AUC值的差距大概是在3%以内。我们也比较了其他的一些明文算法,在这个图里边是-A或者-B,它是用了一些加密的联邦的一些算法去比AUC值,我们的算法都是比其它的算法会高一些,但我们会比明文的算法大概低三个AUC值,在3%以内。第二个是它的运算速度,从这个截图看到,对比了16,000个样本,我们的算法和明文算法去比的话,我们的速度大概是明文算法的6倍,也就是明文算法如果用一分钟的话,我们会用六分钟,这个已经是非常好的效果了。这个地方我们也提到,我们现在用的这个Paper里边是16,000个样本,如果样本增加到10万个,或者再往上增加,我们这个算法的运算效率会更高。那么我们SecureGBM和明文算法的LightGBM,双方数据在一起,比较了在训练集上的AUC值和F1值,大家会看到有一条红线和一条蓝线,在截图里面红线和蓝线绝大多数时候是靠在一起的,走势是相同的,非常的接近。说明我们的这个算法和明文的LightGBM的算法,在AUC值、在F1、在训练集上和测试集上,达到了非常类似的一个效果。第三种算法基于深度学习,PaddleFL,是在我们百度自研的一个开源的深度学习框架飞桨的基础上,研发出来的开源的联邦学习框架。下面是开源框架的github的网址,通过PaddleFL,使用人员可以很轻松的去复制和比较不同的联邦学习算法,也可以在分布式的大规模集群里面去使用。这种PaddleFL主要用在深度学习算法里边,用在计算机视觉、自然语言处理和推荐算法的一些领域,也提供一些传统的机器学习的训练策略。比如说像多任务学习,还有一些迁移学习、主动学习等等,我们底层也提供基于分布式的训练和Kubernetes的训练任务的弹性的调度能力,可以进行全站开源软件的侵入和部署,下面是基于我们的飞桨的一个的架构图。接下来是编程模型、参数服务器、到端侧训练和弹性调度,再往上是我们联邦学习的训练策略及应用。联邦学习策略这块我们也有纵向的联邦学习,刚才提到的PrivC的逻辑回归,横向的联邦学习,还包括DPSGD基于差分隐私的随机梯度等等。我们也有常态的一些机器学习,像迁移学习,多任务学习,主动学习等基于联邦学习的任务,还有基于深度学习的自然语言处理、视觉、推荐这一块的学习任务,都是在PaddleFL的基础上来做深度联邦学习的建模。PaddleFL的架构设计,图的左边叫编译Compile Time,是首先通过联邦策略,去设计一些算法策略,然后在中间设计训练策略,再用分布式的配置,合成以后,传到中间任务的调度上面。任务调度再传到参数的任务和训练的任务上面生成了job以后,再传到这边运行。运行这一块有参数的服务器和worker,再下面是调度器,整个就会把服务提起来,然后进行分布式的训练,这是PaddleFL的架构设计。同理,我们也有基于MPC的联邦学习,分成三部分,一是图右部分,基于数据的准备,首先有私有数据的对齐和数据加密及分发。二是训练和推理过程,和Paddle的运行模式一样。首先要定义协议,在策略训练和推理完成后,就会到这个图的最右边进行结果的重构。这一块就会把模型的结果或者预测结果,由加密方以加密的形式输出,结果方可以收集加密的结果,在PFM工具中进行解密,再将明文的结果传递给用户,就完成了整个MPC的联邦学习过程。安全保证是金融企业最高优关注点我们先看看现有的模式,现有的模式只有几个,在没有用到联邦学习的时候,状态是自己的IDC机房的网络和外界是隔离的,没有联通互联网,数据不进不出,因为只用到自己的核心系统的数据,数据是物理隔离的。但是这个模式最大的问题,就是在它的建模过程中,会存在着一些天花板,比如刚才提到的KS值,如果做到0.35了,就再也不能再往上做了。模型效果更多的取决于特征工程,而他又没有用过外面的无论是互联网,还有政府,一些运营商的一些领域的数据,那么一些风控也好,营销的行为它是拿不到的,模型的上限是由多维度、多样性来决定的,所以达不到很好的建模效果。于是就衍生出来第二种模式,叫标准分的调用模式,标准分的第二个模式,它也是有自有机房,但是它的网络变成不是隔离的了,而是单通道的,就是它的数据只进不出。在网络这块,因为开了一个单向的通道,有可能存在一些被黑客攻击的风险,这个标准分的调用也有一些弊端。大家知道,进来的只是一些标准分,也就是说,外面的数据过来的可能就是一个变量或者两个变量,它是一个高维特征压缩以后的、降维以后的一些特征的输入,每次输入只有那么两三个特征。这种高维特征压缩降到两三个维度以后,有非常多的特征信息是损失了的,所以它提升的建模效果在信贷场景可能只提升那么一两个点,比如像KS值是0.35,提升到0.37、0.38就到了天花板了。我们今天谈到联邦学习的模式,它的数据通道是双通道的,双方要进行梯度或模型参数的交换。首先,双方数据对上面的一个中间节点要进行上传,但是它的原始数据没有出域,它的参数数据或者模型的参数或者梯度参数,是通过加密的方式来出域的。从这个角度来看,因为它的网络通道打开了,存在潜在的被黑客去攻击的风险。梯度参数的话,从现在的业内的研究来看,也存在一些被反解,或者一些隐私被攻击的方法。还有一个,它有一个强烈假设,就是需要参与的双方或者各方,需要满足诚实、半诚实模型的原则,如果有一方有严重的欺诈,去改变了模型的一些参数,或者是一些游戏规则,模型的安全也会受到一些挑战。这是联邦学习目前和上面的现有模式、标准的模式相比,所面临的一些优点和缺点。那么这里会就提到模型提效,模型提效是一把双刃剑。现有模式下,在右边的这样一个方程式,目标标签Y是来自于金融企业本身,它的X特征也是来自于这家企业,企业只用自有的数据建模,没有外部数据带来模型效果提升,就会面临天花板。我们再看联邦学习这种方式,刚才提到,通过梯度参数的交换来建立模型,那么基本上双方数据没有降维,外部提升的最大好处就是,带来的模型效果提升非常大,与明文相比的话,它的精度损失基本上还是比较小的。但是,在和很多金融企业沟通后,知道它有非常大的短板,企业有各种各样的顾虑。1.建模的过程中,即使想用联邦学习来进行建模,金融企业很多时候并不愿意把自己的特征放进来,但是可能只会将自己客户的ID和目标变量Y放进来,因为金融企业会觉得用联邦学习来建模,有可能存在一些数据安全的问题。2.他们也希望拿到一些数据以后,再做二次建模,以满足金融监管的要求,因为在金融监管这一块,特别是在信贷风控的场景,希望金融机构要自控这个模型本身,而不能把这个模型交给外部的机构去控制。安全保证和数据提效前提下的得与舍在数据的安全保证和数据提效的前提下,联邦学习还要面对什么样的得和舍呢?第一个,从运算速度来看,现有的银行在自己的机房里面进行明文计算的数据建模,它的特点是运算速度很快,可以用像spark、Tensorflow、PaddlePaddle等分布式技术去做这种很成熟的运算。但是到联邦学习就不一样了,刚才提到,它的训练速度至少会比明文计算,少则慢一个数量级,慢10倍几十倍,也有慢两个数量级几百倍的这种可能性。第二块就是它现有的分布式技术还不太成熟,这是他在速度这一块可能需要去考量的。第二个,从算法种类来说,明文算法它是基于Python的开源社区,算法生态非常多,上千种上万种,顶级论文的开源代码,基本上就是按天、按周来迭代,更新的频次非常快。但是在联邦学习的算法过程中,要考虑到数据参数的加密,所以它的研发非常困难,我们的算法种类相对而言都是比较少的。业界现在能看到的也就是那么几种或者几十种,并且也不可能把最新的算法研发出来用在联邦学习这个领域。第三块,就是产品的应用性,因为现在基于明文数据的这种算法,AI开发平台有非常多,支持多种框架,还有它和数据的中台的融合,非常好对接。那么对纯代码方式来讲,金融行业去使用时,因为金融行业很多用户也不是经常做coding,所以他的学习曲线比较难、比较高。刚才也提到如果用代码这种方式,它跟这个操作系统有些时候需要linux shell脚本方式进行交互,那么它的安全性可能会存在一些缺陷。百度的度信平台在这一块用纯界面的方式,也面临着一些开发的周期和实施的难度。这个是联邦学习与建模要考虑的问题。所以我们在考虑安全,在考虑数据对建模效果业务绩效的前提下,我们在运算速度上,在算法的种类的选择上,在产品的应用上,都做了一些权衡和一些损失,但有些时候这种损失和这种权衡是值得的。下面一点,就是百度金融专有云,如果是联邦学习在我们的金融云、专有云上面进行部署的话,我们还额外提供七重的数据安全保障。这七重的数据安全保障在这个图里边用1234567都标注出来了。一块是我们提供异地的灾备,我们在武汉、北京和上海有异地的百度金融云专区。在数据的交换过程中,我们会提供一些芯片级的算法级的加密,包括在网络的通路上,也提供一些加密的传输,让加密的数据被截取以后都是不可用、不可解的。我们参与方的数据在云上的链路也好,在云上的一些硬件的里面,双方都是互不可见的。安全的数据脱敏方法和合规制度保障在完成了整个建模的过程以后,比如说金融企业的数据要有用户要查处,最后模型在使用的时候,有一个数据的健全,如果没有授权的话,是不可以去使用产出模型的。除了联邦学习以外,我们在整个云上、在物理链路上、存储量上、硬件上做了各种各样的加密去保证安全,而不只是运用了联邦学习技术本身,或者只是开发一个平台。在和金融企业的沟通中,我们发现,即便双方要进行联邦数据的融合建模,也可以采取刚才说到的,双方先有两个数据宽表,然后再进行融合的联邦学习。在生成这两个双方的数据宽表的同时,还可以采取一些更加安全的数据脱敏方法,用的比较多的就是K-匿名化,这个是保护客户数据隐私的一种重要方法。我们希望双方在生成数据宽表的时候,甲方和乙方都能够采用类似于匿名化的技术,让双方的原始特征数据脱敏得比较彻底,不能够被反推。虽然联邦学习本身也非常安全,在这个基础上,我们能够用更多的数据脱敏的方法。右边这一种也是类似的,我们会用差分隐私的一个方法,在数据集中里面产生一定的噪声,这种随机造成它可以通过一些概率分布前置来产生,这样就在设计过程中很难去推断出客户的一些隐私。和金融机构合作时,在数据的安全管控上,我们也会提供一整套的安全的合规的保障制度。首先是从公司的治理层面,数据和流程层面及安全的能力层面,我们从不同的角度去看这家金融企业和它合作的另外一个互联网企业,只要用到度信平台,我们会提供一整套的关于安全保障机制的建议。还有一块就是数据的生命周期安全,我们考虑到六个环节,数据的收集和产生要合规,我们有数据的分类分级和安全日志。那么在传输和传递过程中,有加密和传输的安全的监控。第三块就是存储,在存储的安全和数据的加密备份这一块,也要考虑安全。第四就是它整个数据的加工的环境,使用方和用户授权等等,也要保证安全。第五个环节涉及整个的流通与共享,包括对内流通和对外流通,我们要考虑相关的安全性。当我们使用完联邦学习以后,也要有相应的动作,不要让数据留存在双方的服务器里边。整个的安全制度合规保障和数据的生命周期,都是我们在实践中慢慢总结出来的。对于整个联邦学习,额外增加了一些针对金融行业更加安全的一些举措和方法论。我们也通过度信在这样一个平台的实施过程中,慢慢把这种方法论传递给金融机构,传递给合作方,让我们整个在运用联邦学习的过程中,更加保证整个数据的安全,让数据可用不可见。
6月30日,易居企业集团执行总裁 克而瑞CEO张燕在“2020易居数据资产大会”作了“不动产数据资产进化论”的主题演讲。张燕提到,克而瑞的产品应用,已经从以住宅为核心,扩容至整个不动产领域的核心节点;同时,克而瑞通过建立的数据中台和业务中台,实现了数据治理、算法构建和算力的升级。完成了不动产数据资产化的价值闭环;在未来,克而瑞将开放数据资源库、数据中台技术能力、数据应用场景合作和数据资产交易平台,共同打造开放共建的数字生态圈。 全文如下: 克而瑞的进化 各位克而瑞的新老朋友,大家好。2020年已经过去一半了,在过去的这半年时间中,大家可能已经习惯了线上见的方式,这可能是疫情带给我们的某种变化,等到疫情过去后,或许我们已经接受并且熟悉了这样一个变化。同样,类似的变化也发生在行业,发生在企业当中。 熟悉克而瑞的朋友会知道,我们是一家深耕在不动产行业,进行大数据应用和服务的公司。当克而瑞熟悉的数据变成了数据资产,那么克而瑞本身会发生哪些变化呢?这是我们今天想跟大家一起来探讨的话题,而我们把这样的一种变化称之为进化。 什么是数据资产 首先,我们来看一下什么是数据资产。数据的初始阶段是杂乱、无序且单位价值低下的。但数据可以通过清洗、梳理这样的数据治理过程,之后再通过构建出算法、模型,最终输出成数据的产品应用。当最终形成了数据资产,那么它便是相对可靠、稳定、有价值并且能够变现的。我们把这样的过程称之为不动产的数据资产化过程,而过去的15年中,克而瑞正是在一一践行这样的过程。 克而瑞如何实现数据资产的进化 那么克而瑞如何来实现数据资产的进化这也是我们今天探讨的核心主题,克而瑞的变化到底在哪里?我们可以从资源、算力、应用和模式这四个方面来一起探讨。 资源 扩容1:以新房数据库为主,扩容至全不动产领域数据库并举 多元异构的数据库是整个大数据应用的基础,它的发展方向首先是扩容,其次是颗粒度的深化。 扩容,克而瑞最初是以一手住宅为核心的方向去建立整体基础数据库,以新房为主。而从过去的两三年开始,克而瑞完成了整个不动产全域的数据库建设,包括商业、办公、产业、物业管理以及城市租赁等非住宅领域,今年更是启动了在地产金融和证券行业的应用,也包括新技术应用到不动产行业中形成了地产科技,上述几大核心领域中我们都进行了结构化和非结构化的数据库建设。 扩容2:以结构化数据为主,扩容至与非结构化图文数据并举 其次,整个大数据应用中,非结构化数据应用占八成以上,但地产行业的结构化数据在过去的应用中占到了主力,占比将近80%,比例正好颠倒。 过去两年中,如何从原来我们应用的报告,新闻资讯、从一些图表图文中去将非结构化的数据实现结构化,这是克而瑞在做的从数据库的源头去做的一个扩容。我们希望未来能够做到更多的非结构化数据的清洗、储存以及利用。 深化颗粒度:数据从中宏观下沉到微观、从静态为主到动静并举 颗粒度深化是另外一个范畴。POI数据是非常庞杂的,我们可以从各种源头获取,但难的是形成适合于不动产领域的相对完整的标签体系,并且能够做到全国覆盖。克而瑞已经完成了深耕不动产行业的完整POI数据库的建立。 其次,在区域经济和板块研究中,我们经常会用到栅格数据,将土地、项目以及配套等相关数据,下沉到1×1公里的栅格当中。在不断的数据产品应用过程中,克而瑞已对全国所有城市实现了栅格信息全覆盖。 如果说栅格和POI还是对于行业数据和静态数据的进一步颗粒度深化,那么客户数据则是我们这一两年中着力去深耕的动态数据。到目前为止,克而瑞已经建立了全国54个城市未来3-5个月内将释放的新房购买需求客群的客户画像,包括客户线下动态的群体画像及指标,这其中也包含到了租赁客户。同时,我们也在构建基于商圈和商务圈外围的整体客群数据和客户画像。 算力 治理升级一:进化数据治理标准 有了数据,第二步当然是更好地去使用这些数据,因此在过去两年时间里,克而瑞完成了自身中台的建立,包含数据中台和业务中台。其中数据中台有两个核心方向:数据治理和算法构建、算力的提升。 首先我们做的是打通底层大数据,建立统一的采集平台。根据业务场景和应用形成相对统一的数据应用标准,建立起数据之间的勾稽关系,形成统一的数据平台。同时虽然应用场景和产品有所不同,但在打造产品的过程中会产生相对需求比较集中的产品组件、模块组件以及数据服务组件,它们可以自由插入到很多的产品及应用中去,极大提升整个产品研发的生产效率。 治理升级二:进化数据治理技术 数据治理环节中,我们会应用到一些核心技术。数据识别其实主要是从报告、图表以及文本中提取结构化数据。这类工作过去都靠人工完成,而今天通过机器学习已经可以达到。其次,数据清洗的核心在于规则的建立,通过样本的机器学习,不断地深化机器学习的过程,最终达到数据清洗的目的。 整个数据治理过程中的核心是数据标准的建立,尤其是不同源数据之间用同一标准来进行数据勾稽关系的建立。在整个过程当中,我们还形成了数据的预警机制,希望在数据治理过程中就能够发现数据可能会出现的问题,而不必等到应用端的产品出来之后才发现这些问题。 算力升级一:结构性数据算力和算法升级 通过完整的数据治理之后,我们另外的一个核心工作便是通过算力的提升,来有效、快速地实现算法的构建。比如公允定价,在刚刚提到的栅格系统应用中,我们基本可以做到只要点击任意一个栅格基本单位,那么这个单位所对应的区域价值(即俗称的地价)就可以直接显现,而且是秒级回应。再比如大家熟悉的,我们在做前测时候都会去做的产品配比,过去更多的是靠人工、靠自己的经验来做方案的优化。而今天我们通过机器学习,可以通过设计出容积率、货值、利润最大化等核心条件,来筛选出来最优方案。每进行1%的调参,机器会进行800万次计算,最终把TOP10的最优方案推到前台,而这样的过程在2秒以内就能完成。再比如我们在寻找价值洼地的时候会经常使用的“人口密度”这个参数,它是没有标准数据的,我们通过自己构建的楼盘字典,再加上人口统计数据,通过算法建立之后,来算出每个板块,甚至于比板块更小的单位的人口密度,来支撑一些后端应用。另外,算法构建也不断的应用到了诸如市场预警以及城市周期等克而瑞的各类型线上产品中。同时,所有的算法,我们都能够实现数据的回测。 算力升级二:非结构化数据AI技术升级 刚刚提到的这些通过算力能够快速形成的算法,主要是集中使用在结构化数据中,而非结构化数据也是我们这一两年当中着重去深化和学习的。我们刚才已经探讨过,克而瑞在研究、服务输出的过程中会应用到大量的报告,包括上市公司的中报、年报;包括很多克而瑞自己撰写的报告;包括很多的新闻资讯、文章等等。而通过NLP的自然语义挖掘技术,进行深度的机器学习,最终我们已经形成了今天适用于不动产行业的非结构化数据的知识图谱,它可以应用的范围更广。在下半年克而瑞要发布的云图系列产品当中,它可以应用到舆情监测,也可以应用到智能营销等环节中去。 应用 系统产品扩容:从新房数据系统为主,扩容至全不动产领域数据系统 刚才我们已经提到了数据在最终应用场景中的输出。而大家熟悉的克而瑞提供线上产品和线下服务的传统模式,也发生了变化。原来克而瑞更多是以系统产品和报告提交给客户,而今天我们首先对内容和范围做了扩容,从以新房和住宅为核心,扩展到了不动产的整个领域,包含我们这两年一直在做的基于资管的资管云、投管云;包含我们在产业深耕过程中打造的文旅数据系统;包含我们今年成立物管事业部之后,完整地构建了起了第一个物管行业数据系统;也包含今天的城市租赁系统等。大家会发现,克而瑞已经从住宅跨越到了非住宅,从开发领域更多地踏进了运营领域。 应用载体升级:从解决方案为主,进化至智能BI系统并举 克而瑞除了提供数据产品,同时也做很多行业研究、企业研究,提供咨询报告给我们的客户。但是在今天,我们可能将这样的服务方法和载体也进行递进和迭代。比如我们可以提取数据,生成多种业务看板,最终形成商业洞察,这就是智能BI的应用。今年下半年会发布的云图系列产品中的云图洞察,就是按照这样的方向及逻辑在实现。最终我们希望看到的是克而瑞整个商业模式的进化。 模式 打造数据资产交易平台 整个行业都已经熟悉了克而瑞提供线上系统和线下服务。在这个过程中我们也在思考,如果我们的客户并不需要一个完整的系统产品,而只需要一些碎片化的数据,或只需要报告中的某些部分。同时这些客户或许也不再是以开发企业为核心,可能会扩展到广告公司、上下游产业链中的供应商,甚至还有跨行业的使用者。如果克而瑞给他们提供数据服务的话,又会是怎样的一种方式?这也是我们今天构建数据资产交易平台的一个很大动因,我们推出了添玑数据商城,本着这样一个愿景,在最终产品输出端口来形成价值闭环。 生态圈全景图 讲到这里,我们再来看克而瑞的生态全景图,或许会更清晰明了。首先,应用大数据的相关技术,构建多元异构的不动产数据资源库。第二步,在数据大脑平台上,所构建的算法、提升的算力得以不断进化。最终我们构建起基于区块链技术的数据资产交易链,这样的过程形成了数据资产化的完整闭环。 而这个生态圈的打造,核心是为了开放和共建,克而瑞将开放整个生态体系。 在这个体系中,我们开放数据资源库,拥有数据的供应商可以通过数据交换的方式和克而瑞进行互补,来丰富和扩大各自的数据库。除此之外,我们也可以跟有一定技术实现能力的合作伙伴,开放数据库给他们,共同形成新的产品和应用。 其次,我们也会开放自己的中台技术,通过技术赋能,去促进行业内甚至跨行业的整个不动产大数据的应用和服务。 至于开放应用场景的合作,我们跟跨行业或者行业内上下游产业链中的很多伙伴都探讨过这个问题,大家希望我们能够共建数仓,基于这个数仓最终形成不同的场景应用。克而瑞贡献了比较多的线上的系统产品,但仅如此是远远不够的,我们希望有更多的伙伴加入进来,使得行业在数字化进程中诞生更多的产品及应用。 而最终,我们希望在实现价值闭环的过程中,形成资产交易的完整平台。今天这个平台刚刚起步,更多的是克而瑞把自己的数据资产贡献出来,而在未来,数据的使用者也可能成为数据的提供者。虽然这种身份的转化或许在今天还未被大家清晰地意识到,但随着这个交易平台慢慢被接受,参与到其中的人越来越多,它的成长及扩容,将带动整个不动产行业的资产交易成为现实。 共同打造开放共建的数字生态圈 我们回到今天的主题——构建行业主链、共建数字生态,在这个完整的生态圈中,克而瑞非常希望通过自身的递进、迭代,成为生态圈中最重要的一环。 谢谢大家。





 登录
登录






 工商服务
工商服务 危机公关
危机公关 金融律师
金融律师 app开发
app开发 财税服务
财税服务 金融牌照
金融牌照 网站建设
网站建设 知识产权
知识产权 企业征信
企业征信 审计评估
审计评估